Я вчера сам JhaoDa ввел в заблуждение. У меня опечатка была в коде, не заметил вечером. Вставка пачками давала результат значимый. Щас потестил вариант с вставкой по 6к за секунд 6-7 заполняется база из 160к записей
В любом случае, это выглядит тоже как решение. Лично, предполагаю, пойду по варианту от mayton2019
mayton2019, через файл вставка проходит быстро - 2,5 секунды в среднем. То, что надо
Я правильно понял с enrichment csv, что я могу сперва обработать csv-файл, трансформировать данные как мне надо, сделать своего вида csv и импортировать его в базу ?
В моем случае можно и после вставки уже пробежаться по элементам и трансформировать. Интересно по подходу
Да, согласен что 200к это в целом не число для нашего времени.
Была тоже мысль через мускул загнать csv, но мне нужно в рантайме проводить обработку какую-то элемента и определять ему атрибуты (валидный / не валидный / etc..). Через БД процедурой таким заниматься? или считывать базу и апдейтить ?
Выпал из контекста по жизненным обстоятельствам, честно говоря..
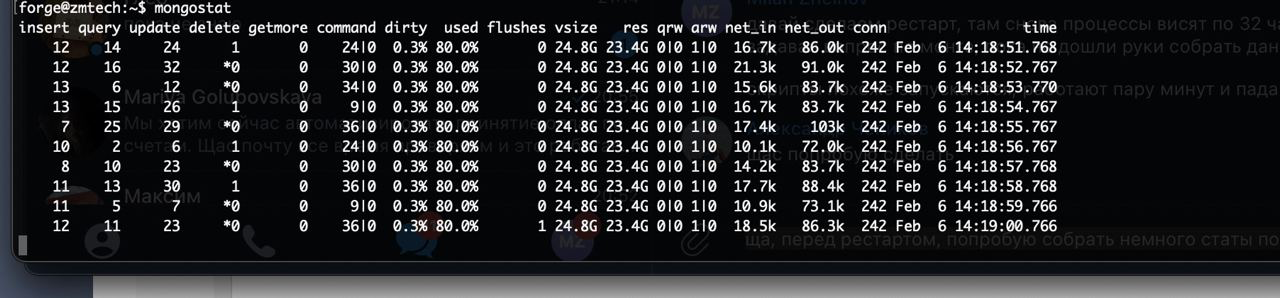
Я собирал инфу по вашим командам еще тогда (эта инфа была перед тем, как у нас забивалась вся ОЗУ на серваке)
SunTechnik, правильно понял, что mongodb выделяет большой кусок памяти при запуске и путем shared memory ее процессы между собой быстро обмениваются данными. Следовательно, при shared memory, на каждом процессе висит тот общий кусок памяти, но отличия мелкие все же имеются ?
Написано
Войдите на сайт
Чтобы задать вопрос и получить на него квалифицированный ответ.