Евгений, нет, я про хранение страниц в memcached или redis с помощью, например, плагина W3 Total Cache. Чтобы при запросе страницы не всегда делались запросы в базу данных, а доставалась закешированная копия из кеша (по сути из оперативной памяти сервера). Тогда нагрузка на базу снизится в разы, а сам сайт будет работать ощутимо быстрее.
Евгений, да без разницы, бот или нет. 30 запросов в секунду - это очень мало, а 1 с на запрос - это много. Я считаю, что даже 500 мс - это обычно тоже весьма много. Я ж молчу про то, что по-хорошему, для отрисовки большинства страниц запросы в базу вообще делаться не должны, потому что должно быть настроено кеширование. Оно у вас, надеюсь, включено?
АртемЪ, ну так-то он прав в том, что "фриланс набит wordpress и прочек cms". На фриланс-биржах крайне много задач по WP и прочим CMSкам. Причем цены на них просто копеечные - лютый демпинг. Там народ за 500 рублей готов целые сайты клепать. Утрирую, конечно, но это реально демпинг.
Евгений, вот статья, где написано как включить лог медленных запросов. Включите их, рестартаните MySQL и ждите, когда там появятся записи. А если у вас проблемы именно из-за тяжелых запросов, то более мощный сервер не спасет - опять столкнетесь с теми же проблемами, когда данных в таблицах базы станет больше.
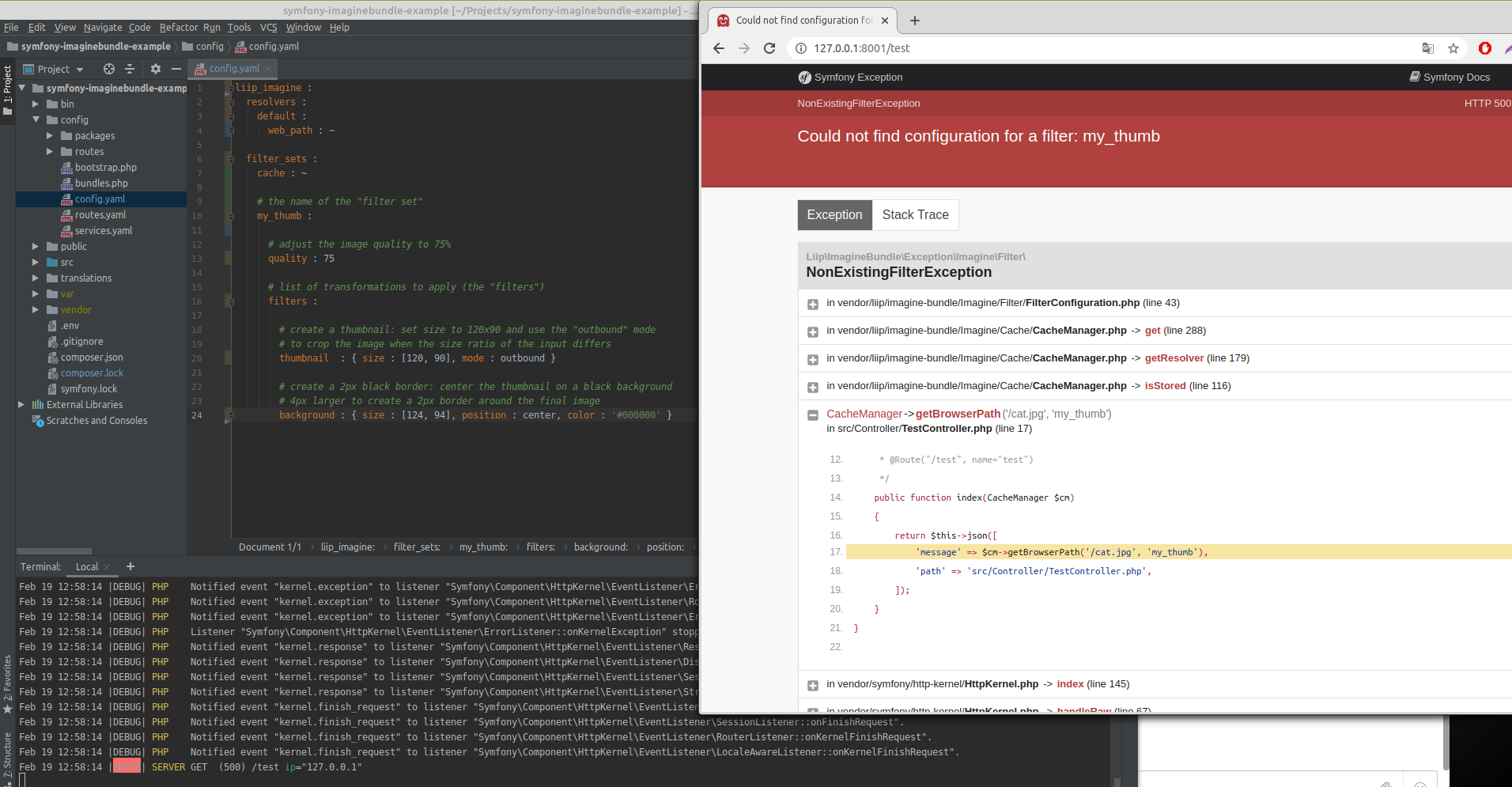
Юрий Битько, спасибо, вроде бы, разобрался. Выяснилось, что надо было не в config.yaml писать конфигурацию, как в доке указано, а в config/packages/liip_imagine.yaml - и тогда ок.
Вот только я один момент еще не понял. Как это все дело кешируется? Вот, допустим, у меня страница, на которой присутствует одновременно несколько десятков картинок (товары, например). Для каждой картинки эта библиотека делает запрос в s3, скачивает изображение, делает миниатюру, которую заливает в папку cache в s3 и отдает ссылку.
И возникает логичный вопрос: чтобы отобразить страницу с товарами, когда у меня протух кеш моего API, эта либа для каждой картинки сходит в s3 и проверит наличие там нужной миниатюры? Если да, то это ж странно получается, как-то не оптимально, особенно если у картинки по несколько миниатюр предусмотрено. Под трафиком это нормально работать вообще будет? Или я что-то не так понял?
Да, у меня ответ API кешируется. Но даже так кеш иногда ведь протухает. И тогда для каждой картинки товара для каждой превью будут делаться запросы к s3 для проверки существования той или иной превьюхи. То есть таких запросов может быть несколько сотен - и API будет отвечать на такой запрос аж несколько секунд. Выход, как я понимаю, только один: написать свой резолвер реализовав интерфейс ResolverInterface?
Юрий Битько, спасибо, но не решило проблему. Сделал сейчас прямо копи-пейст из доки - та же ошибка. Есть подозрение, что бандл вообще по какой-то причине даже не читает файл config.yaml - потому и не видит конфигурацию для фильтра.
Георг Гаал, да, но скачивает он в свою папку в /home/gitlab-runner/builds/<рандомный набор букв (возможно, часть хеша коммита>. А у меня проект в совсем другой директории и вообще не в хомяке.
run182, написать простой парсер, который обходит все страницы в карте сайта и из html страниц выдирает все теги ссылок, в атрибуте href которых ищет нужную.
lil_web, я имел в виду NextJS. То, что ты скинул - это один из примеров, там их много. Да, я примерно так и юзаю) Я предложил NextJS, потому что он решает твою проблему.
кажется, он меньше напрягает сервер
Кстати, это откуда инфа? Принцип там, по идее, тот же самый
Илья, получается, что на сервере работает js-скрипт, который висит на 80-м порту. Когда приходит запрос (открытие страницы сайта), рендерится js-страница на сервере (в том числе в getInitialProps делаются запросы к API бэкенда) - и отдается готовый html. При последующих переключениях между страницами делаются уже обычные ajax-запросы и рендерится все в браузере. То есть да, для первоначальной загрузки страницы запросы к API делаются как бы прямо с сервера.
zlodiak, это как раз легальный, если можно так выразиться, нормальный вариант. Это абсолютно та же самая задача. Смысл парсить, если есть готовое API, возвращающее json? И для питона готовая библиотека есть к тому же.