print ( функция (аргумент...) ) import re
f=open("....")
text=f.read()
addr='addr=\\"(([0-9]{1,3}[\\.]){3}[0-9]{1,3})"'
a=re.search(addr, text)[1] #re.search выдает набор: весь результат и подргуппы, нужна конкретная подгруппа, в которой адрес, аналогично со вторым re.search
cpe="osmatch\sname=\"(.?HP.+?)\".*\n.*<cpe>(.+?)<"
c=re.search(cpe, text)[2]
print (a,c)
45.33.49.119 cpe:/h:hp:p2000_g3import urllib.request
import json
import requests
import time
import pprint
FOLDER_ID = "......." # Идентификатор каталога, даётся при регистрации на яндекс-платформе
IAM_TOKEN = "..........." # IAM-токен, даётся при регистрации на яндекс-платформе
path1="C:\\work\\"
list1=('4.ogg', '9.ogg')
def short_audio (list1, path1): #берёт ogg-файлы по списку list1, файлы лежат в директории path1
for a in list1:
with open(path1+a, "rb") as f:
data = f.read()
params = "&".join([
"topic=general",
"folderId=%s" % FOLDER_ID,
"lang=ru-RU"
])
print ("params=", params, "data",data)
url = urllib.request.Request("https://stt.api.cloud.yandex.net/speech/v1/stt:recognize?%s" % params, data=data) #пересылает содержимое ogg
url.add_header("Authorization", "Bearer %s" % IAM_TOKEN)
print (url)
responseData = urllib.request.urlopen(url).read().decode('UTF-8')
decodedData = json.loads(responseData)
if decodedData.get("error_code") is None:
print(decodedData.get("result"))
return
short_audio(list1, path1)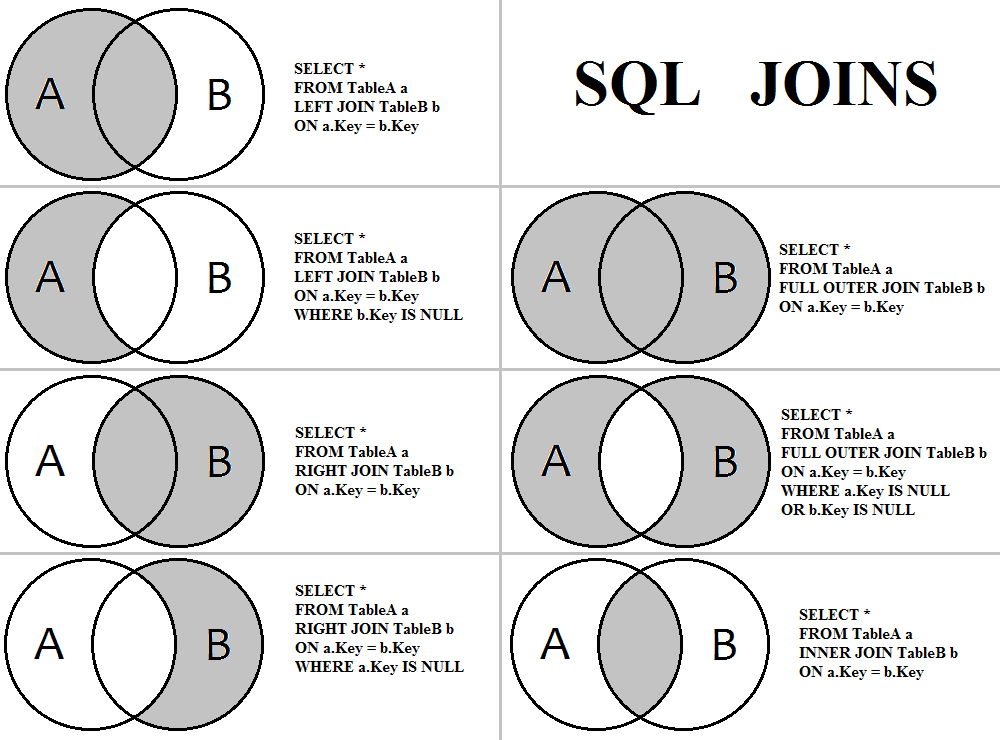
if city in collection.values(): # если есть среди значений словаря collectiondict1['level1']['level2']['level3']=999 data[1:].sort........import pandas as pd
p1=pd.read_csv('c:\\work\\csv1.csv', sep=';') #кодировка по умолчанию utf8, названия столбцов в строке 0
p1.sort_values(by=['col1','col2','col3'], ascending=False) #можно задавать несколько столбцов, но вверх или вниз применяется только ко всем вместе, т.е. для того, чтобы было в разные стороны, нужно будет 2 раза сортировку делатьmin1=[min(dict1)] #ключ с минимальным значением
print (min1, dict1[min1]) # распечатать ключ и значение)[{'cena': '\n \t 2\xa0345\xa0000\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-lx-570-vnedorozhnik-2011-g-v-probeg-117000-km-avtomat-5-7-l-advert740313755.html'},
{'cena': '\n \t 1\xa0200\xa0000\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-gx-470-vnedorozhnik-2004-g-v-probeg-133569-km-avtomat-4-7-l-advert750625481.html'},
{'cena': '\n \t 1\xa0320\xa0000\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-rx-270-vnedorozhnik-2011-g-v-probeg-115000-km-avtomat-advert749088541.html'},
{'cena': '\n \t 1\xa0500\xa0000\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-gs-250-sedan-2013-g-v-probeg-142145-km-avtomat-2-5-l-advert753188137.html'},
{'cena': '\n \t 1\xa0839\xa0999\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-lx-570-vnedorozhnik-2008-g-v-probeg-265000-km-avtomat-5-7-l-advert752860724.html'},
{'cena': '\n \t 845\xa0000\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-rx-350-vnedorozhnik-2006-g-v-probeg-196000-km-avtomat-3-5-l-advert752339702.html'},
{'cena': '\n \t 1\xa0400\xa0000\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-ls-460-sedan-2012-g-v-probeg-390000-km-avtomat-advert744369992.html'},
{'cena': '\n \t 3\xa0900\xa0000\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-lx-limuzin-2010-g-v-probeg-44000-km-avtomat-advert699227821.html'},
{'cena': '\n \t 3\xa0400\xa0000\xa0руб.\n \t ',
'link': 'https://irr.ru/cars/passenger/used/lexus-lx-570-vnedorozhnik-2013-g-v-probeg-75000-km-avtomat-advert753194033.html'}]import re
import urllib
regexp1='(\/diff\/\d{1,2}-\d{1,2}.?doc)'
f=urllib.request.urlopen('http://1311.ru/info/info.php') #открывает, возвращает объект http (не текст)
b=f.read() #читает из него в bytes
text=b.decode() #из bytes в utf-8 (кодировка по умолчанию, поэтому в аргументах декод можно не писать) переводит в текст
out=re.findall(regexp1, text)
#далее, зная адрес сайта
for i in out:
print ("http://1311.ru"+i)
http://1311.ru/diff/16-09.doc
http://1311.ru/diff/17-09.doc[(user.email,user.name) for user in (jane, joe)]
Out[26]: [('jdoe@example.com', 'Jane Doe'), ('jdoe@example.com', 'Joe Doe')]
[(user,user.name) for user in (jane, joe)]
Out[33]:
[(<__main__.User at 0x1614587a390>, 'Jane Doe'),
(<__main__.User at 0x1614587a1d0>, 'Joe Doe')]{joe:joe.name, jane:jane.name}
Out[46]: {<__main__.User at 0x1614587a1d0>: 'Jane Doe'}result = cursor.fetchall()
for x in result :
if x == (2222,): # зачем запись (2222,) ? Это тупла (неизменяемый список) из одного элемента, он не равен числу 2222
print(x)
else:
print ("ops")b'\xd0\x94\xd0\xb0, \xd0\xbf\xd1\x82\xd0\xb8\xd1\x86\xd1\x8b \xd0\xbe\xd0\xbf\xd0\xb0\xd1\x81\xd0\xbd\xd1\x8b "'.decode()
Out[106]: 'Да, птицы опасны "'df['newcol']=...какие-то действия...df['mean1']=df['Value'].mean() # значение mean пропишется в каждой строке столбцаdf['a'], df['b']=list1,list2 #оба списка по длине равны длине колонкиdf.groupby(['Name']).size()
Out[95]:
Name
Igrek 1
Iks 2
zet 1
dtype: int64df.groupby(['Name']).size().index.tolist()
df.groupby(['Name']).size().tolist()
d=dict( zip (df.groupby(['Name']).size().index.tolist(), df.groupby(['Name']).size().tolist() ) )
d
Out[98]: {'Igrek': 1, 'Iks': 2, 'zet': 1}