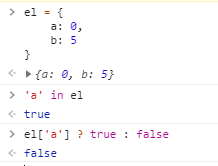
Alex, триггеры, созданные в СУБД, автоматически выполняются по условию, указанному при создании триггера. Например, при обновлении таблицы с очками пользователей можно дернуть триггер, который сделает апдейт в таблицу ачивок
Самый идиотский вариант, который пришел в голову первым - посчитать количество уникальных тегов и сравнить с количеством тегов для каждого товара в таблице связки)
Может, стоит основу кода и страниц выложить? Телепатия это круто, но надо же знать меру)
В том числе, ошибки, архитектуру системы, на чем все крутится.
koliane, ну, тогда можно предрассчитать дерево максимумов по интервалам.
На каждой 1000 точек определить локальный максимум. Потом взять тысячу таких блоков, определить максимум на них, и т.д.
Выбирать интервалы, исходя из удаленности точек и перебирать не точки, а интервалы
koliane, я уж молчу о том, что можно собирать интервалы в виде дерева, и, например, объединять 10 интервалов по 1000 точек в один. Но это на вкус и цвет, имхо, это избыточно для несчастного миллиона точек)
Если бы вопрос стоял о решениях в количесве сотни миллиардов в какой-то степени (вот, я сейчас именно такими и занимаюсь, мне повезло), тогда да, вопрос об оптимизации стоит очень остро)
koliane,
Мои топовые графике в пеинте.
Сделать предрасчет 1000 локальных максимумов на интервалах [0...1000] [1000, 2000] , ...
Пусть есть две точки А и B. От точки A надо найти найти максимум, перебрав 300 элементов справа (до начала нового интервала). От точки B надо найти максимум, перебрав 400 элементов слева. Теперь у нас есть 4 числа - max(a'), max(m2), max(m3), max(b'). Найденный максимум на 4 значениях и есть максимум между A и B.
Таким образом, на интервале, содержащем 2700 точек, мы делаем (300+400+4 = 704) проверки.
koliane, я понял. Ответьте на вопрос - почему Вы прицепились к хранению информации в точке, если есть более быстрые и адекватные варианты, которые я Вам даже могу назвать.
koliane, что сплайны, что интерполяционные полиномы - дикая вещь. Я молчу, например, про Лагранжа, где степень старшего члена определяется количеством узлов исходного дискретного графика.
Хранение формулы - половина беды. Представьте, что у Вас есть полином, выдающий значение в точке по координате. Чтобы вычислить того же лагранжа, надо будет по той же формуле сделать невероятное количество операций. Например, на первом шаге надо будет возвести число в миллионную степень. Потом в 999999, и так далее.
koliane, так Вы определите задачу - надо получить эффективный алгоритм нахождения максимума на дискретном графике, а хранение информации - это Ваше предположение, или же хранение данных является нерушимым постулатом исходной задачи?
koliane, перебор даже миллиона точек - довольно быстрая задача, на фоне остальных вариантов (комбинации, интерполяционные полиномы и тд).
Если нет исходной функции, а есть набор точек, то в любой паре точек каждая из них не зависит от второй так, чтобы можно было восстановить локальный экстремум.