p = 0.6
monet = pd.DataFrame([np.random.binomial(1,p) for i in range(100)])[0]
print(f'Выборочная вероятность орла: {monet.mean()}')
mm = monet.mean()
ss = monet.std()
apost = norm(mm,ss/len(monet)**(1/2))
x = np.linspace(0,1,10000)
fig, ax = plt.subplots(figsize=(18,10))
mean = apost.mean()
std = apost.std()
ax.plot(x, apost.pdf(x), linewidth=2)
ax.grid()
ax.fill_between([mean - 3*std, mean + 3*std], 0, apost.pdf(x).max(), alpha = 0.3)
ax.fill_between([mean - 2*std, mean + 2*std], 0, apost.pdf(x).max(), alpha = 0.3)
ax.fill_between([mean - std, mean + std], 0, apost.pdf(x).max(), alpha = 0.3)
plt.xlim([mean - 4*std,mean + 4*std])
ax.vlines(1/2, 0, apost.pdf(x).max(), color = 'r', linewidth=2)
ax.vlines(monet.mean(), 0, apost.pdf(x).max(), color = 'black', linewidth=2)
Не начав игру, вы не можете узнать матожиданиеПонял вас, я был некорректен, необратив внимание на то, что можно в холостую погонять монеты, т.е. без ставок
Нет, при случайном выборе на длинной серии бросков будете выходить вничью с любой монетой.Да, кажется я поторопился с выводами. Хотя в случае равных вероятностей стратегия ставки на то, что выпало предыдущее, также не даст плодов. Это все имеет смысл, пока не вводится маржа организатора и коэффициенты не занижаются (т.е. можно быть как минимум в нуле). Иначе, необходимо будет как можно с большей вероятностью определять кривая ли монета, при этом используя наименьшее количество тренировочных подбросов.
Это не упрощение, а усложнение. Может быть все монеты чаще падают решкой, тогда ваши шансы на выигрыш в короткой серии бросков будут малы, а в длинной серии будут стремиться к нулю.
Если не ставить такое ограничение, то можно предложить простейшую стратегию: делать ставку на сторону, которая выпала в прошлом броске.
"Собственно на эту сторону и нужно делать ставки, удваивая каждый раз при проигрыше"
vals = pd.Series([1,3,2,5,3,1,2])
fv = 6
def cumscums(vals, fv = fv):
vals_ = []
vals_.append(vals[0])
vals = vals[1:]
for ind,line in enumerate(vals, start=1):
if vals_[ind-1] < fv:
vals_.append(vals_[ind-1] + line)
else:
vals_.append(line)
return vals_
ccc = cumscums(vals, fv = fv)
pd.Series(ccc)vals = pd.Series([1,3,2,5,3,1,2])
fv = 6
def cumscums(vals, fv = fv):
vals_ = []
vals_.append(vals[0])
vals = vals[1:]
for ind,line in enumerate(vals, start=1):
if vals_[ind-1] < fv:
vals_.append(vals_[ind-1] + line)
else:
vals_.append(line)
return vals_
ccc = cumscums(vals, fv = fv)
pd.Series(ccc)vals = pd.Series([1,3,2,5,3,1,2])
fv = 6
def cumscums1(vals, fv = fv):
vals_ = []
vals_.append(vals[0])
for ind in range(1,len(vals)):
if vals_[ind-1] < fv:
vals_.append(vals_[ind-1] + vals[ind])
else:
vals_.append(vals[ind])
return vals_
time_start = time.time()
cumscums1(vals, fv = fv)
time_end = time.time()
print(time_end - time_start)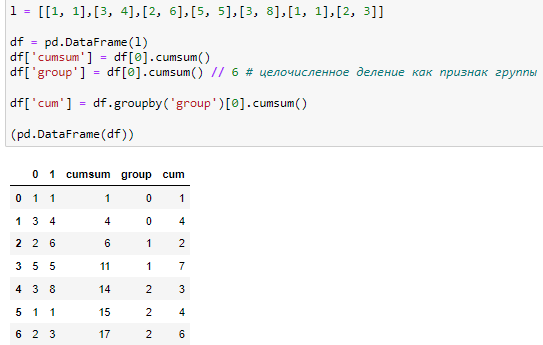
vals = pd.Series([1,3,2,5,3,1,2])
fv = 6
def cumscums(vals, fv = fv):
vals_ = vals[vals<0]
vv = vals.copy()
while len(vals_)<len(vals):
cs = vv.cumsum()
cc = (cs//fv).shift(1,fill_value=0)
vb = cs[cc<1]
vv = vv[cc>=1]
vals_ = pd.concat([vals_,vb])
return vals_
cumscums(vals, fv = fv)