vals = pd.Series([1,3,2,5,3,1,2])
fv = 6
def cumscums(vals, fv = fv):
vals_ = []
vals_.append(vals[0])
vals = vals[1:]
for ind,line in enumerate(vals, start=1):
if vals_[ind-1] < fv:
vals_.append(vals_[ind-1] + line)
else:
vals_.append(line)
return vals_
ccc = cumscums(vals, fv = fv)
pd.Series(ccc)
import pandas as pd
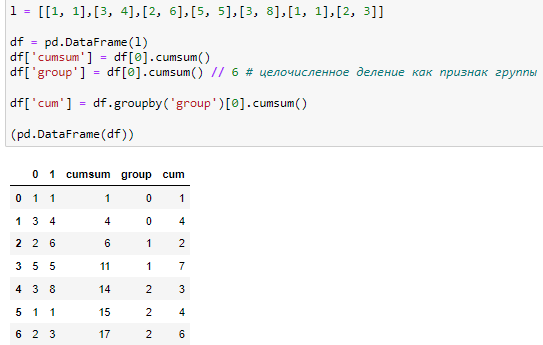
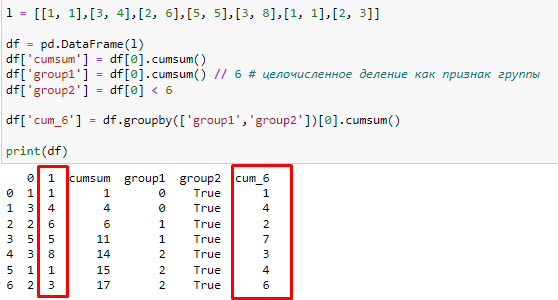
l = [[1, 1],[3, 4],[2, 6],[5, 5],[3, 8],[1, 1],[2, 3]]
df = pd.DataFrame(l)
df['cumsum'] = df[1].cumsum()
df['group1'] = df[1].cumsum() // 6 # целочисленное деление как признак группы
df['group2'] = df[1] < 6
df['cum_6'] = df.groupby(['group1','group2'])[1].cumsum()
print(df)