тут все просто - для промышленной эксплуатации полноценный Linux. для экспериментов, отладки и пр. вопросов при разработке ПО wsl как быстрая замена не нуждающаяся в развертывании.
1 Сделать buckup БД
2 Удалить ненужные записи (тут только delete, т.к. truncate уничтожает все записи, но быстро) Иногда приходится кусками, отдельными транзакциями. Зависит от нагрузки на БД.
3 Обновить статистику
Такая задача называется логирование и решается очень по разному. Нет общих каких-то инструментов, т.к. объем логирования сильно влияет на производительность БД. Поэтому каждый раз ищется компромисс между производительностью и количеством логируемых данных.
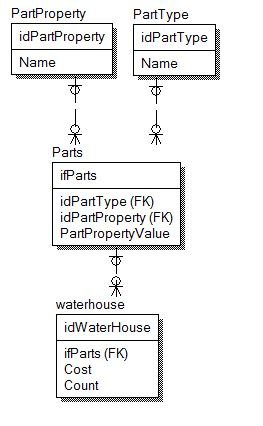
Отделить сущность товар, от сущности "история просмотров" самое лучшее. В сущности "история просмотров" помимо индекса товара хранить дату просмотра. Почти 100% менеджеры захотят отлеживать всякие всплески просмотров и прочую аналитику. Для начала можно все пихать в одну таблицу, по мере роста придется отделить архивные логи (например за год) от оперативных.
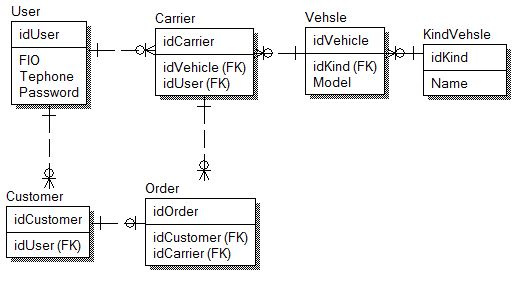
Зависит от того какие бизнес-задачи решают задачи и подзадачи. Сформируйте список атрибутов задачи и подзадачи и сравните эти два множества. Если они равны, то в одну таблицу и внешний ключ самого на себя. Если множества не равны, то в разные таблицы.
Использовать справку по mySQL, например тут
Написать скрипт (утилитку) который, перебирает таблицы в БД, проверяет наличие колонки с именем id и если ее нет добавляет.
Очень просто:
1. Устанавливаете на нее windows
2. Устанавливаете atmel studio
3. Устанавливаете plugin в atmel studio для компиляции ардуиновских скетчей.
4. Полученный hex файл выполняете в симуляторе в atmel studio
5. ...
6. тут как упорства хватит, может и Profit! :)
Если логика агрегирования простая и умещается в один запрос безо всяких курсоров, то лучше сделать sql скриптом SQL в рамках одной транзакции.
Если сложнее и придется использовать курсор, но не больше одного, то так же в sql скрипт. (возможно обложится индексами)
Во всех остальных случаях вынести в приложение с широкими выборками.