The collation (how comparisions are done)
The Unicode organization has been evolving the specification over the years. Here are the mappings from its "versions" to MySQL Collations:
4.0 _unicode_
5.20 _unicode_520_
9.0 _0900_
Most of the differences will be in areas that most people never encounter. One example: At some point, a change allowed Emoji to be distinguished and ordered in some manner.
The suffix (MySQL doc):
_bin -- just compare the bits; don't consider case folding, accents, etc
_ci -- explicitly case insensitive (A=a) and implicitly accent insensitive (a=á)
_ai_ci -- explicitly case insensitive and accent insensitive
_as (etc) -- accent-sensitive (etc)
А с чего начинать?
там нельзя выделить курсор! хоть бы посмотрели прежде чем писать
и у меня debian, а не arch. не все можно легко поставить на debian
Я знаю что смогу его изучить так
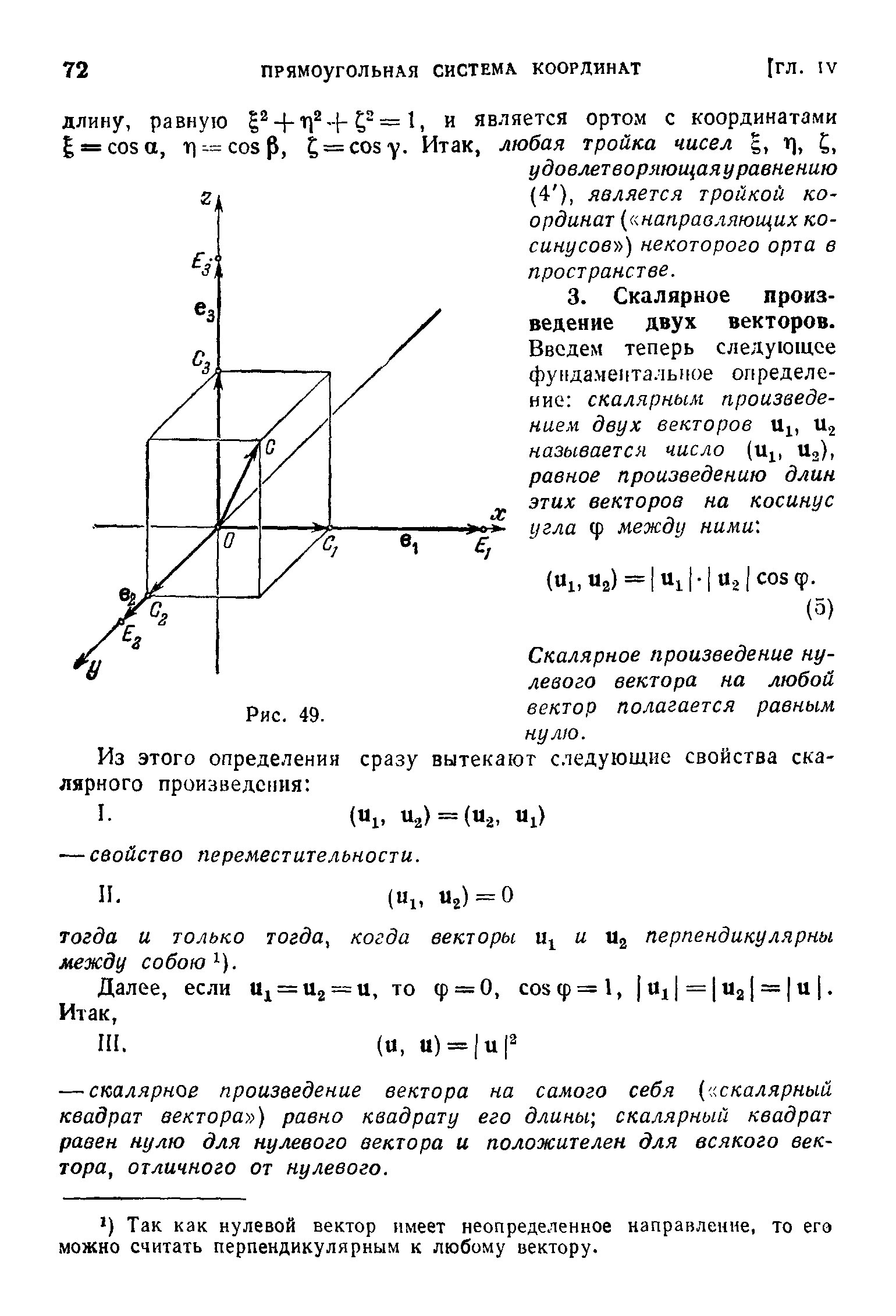


collation в переводе с английского означает "сопоставление". Влияет на то, как сопоставляются значения. А кодировка одна и та же.