Как правильно подгружать новости из бд по «свежести»?
Пишу парсер новостей.
Сейчас попытаюсь понять, как правильно записывать дату и время парсинга в бд, а также как потом вытаскивать новости по дате.
Прочитал про работу с датой на пхп и в мускуле. Запутался.
Надо:
1. указывать дату и время парсинга для каждой новости.
2. При загрузке сайта выводить 10 самых свежих новостей из выбранной категории (в каждой категории по несколько таблиц. В некоторых категориях новостей за "сегодня" может вообще не быть).
3. Аяксом, при нажатии кнопки "показать ещё" подгружать следующие 10. И так далее.
4. Отдельным элементом показывать дату, отдельным - время. (Условно, дату нужно крупным жирным шрифтом, время - мелким серым)
Я думал так - дату формировать в пхп и хранить в бд строкой. А доставать с помощью LIKE. Но тут написали, что это не правильно.
Какая в этом случае правильная логика? Наверняка ведь задача типовая.
Но это легко, я сам так могу выбрать. А что делать, если таблиц несколько? Допустим, пять. За "сегодня" - по одной новости в трёх таблицах. За "вчера" - по две в каждой.
В общем, нужно заглянуть в каждую таблицу, и выбрать не последние записанные, а выбрать по дате и времени. Допустим, что в первой таблице есть новости за "сегодня 14:58" и "сегодня 13:00", а в другой таблице крайняя новость - "сегодня 13:30". Вот надо чтобы на страницу их вывело : 1. 14:58, 2. 13:30, 3. 13:00.
Пока я думаю так: выбрать из всех таблиц все новости за "сегодня". Пока длина массива <10, то выбрать за "сегодня-1", "сегодня-2" и т.д.. Затем отсортировать по дате. И уже с 0 по 9 элемент вывести на страницу.
А с какой целью вы новости по разным таблицам раскидали? Ежели без этого никак, то делаете сложный запрос с join, вложенными select-ами и прочей радостью. Конкретный пример не видя вашей БД дать сложно.
Согласен с Александр Лыкасов, в том что разделение на таблицы выглядит не очень оптимально.
В данном случае могу предложить такой вариант решения:
SELECT * FROM (
-- last 10 records from each table
SELECT * FROM news1 ODER BY added_at DESC LIMIT 10
UNION ALL
SELECT * FROM news2 ODER BY added_at DESC LIMIT 10
UNION ALL
SELECT * FROM news3 ODER BY added_at DESC LIMIT 10
UNION ALL
SELECT * FROM news4 ODER BY added_at DESC LIMIT 10
) ODER BY added_at DESC LIMIT 10;
Slava Rozhnev, ого... Спасибо. То есть, это решение моей задачи средствами бд. Я о таких приемах и не знал.
Можете проконсультировать по поводу организации бд?
Вот сервис: otovsydy.ru (пару дней был не оплачен хостинг, потому там некоторые новости устаревшие, а собранные будут с одним и тем же датой и временем)
Суть - парсинг новостей.
Поскольку способы отображения новостей на сайтах разные, для каждого сайта написан свой метод парсинга. Некоторые сайты отображают похоже, для них метод один и тот же, но разные селекторы.
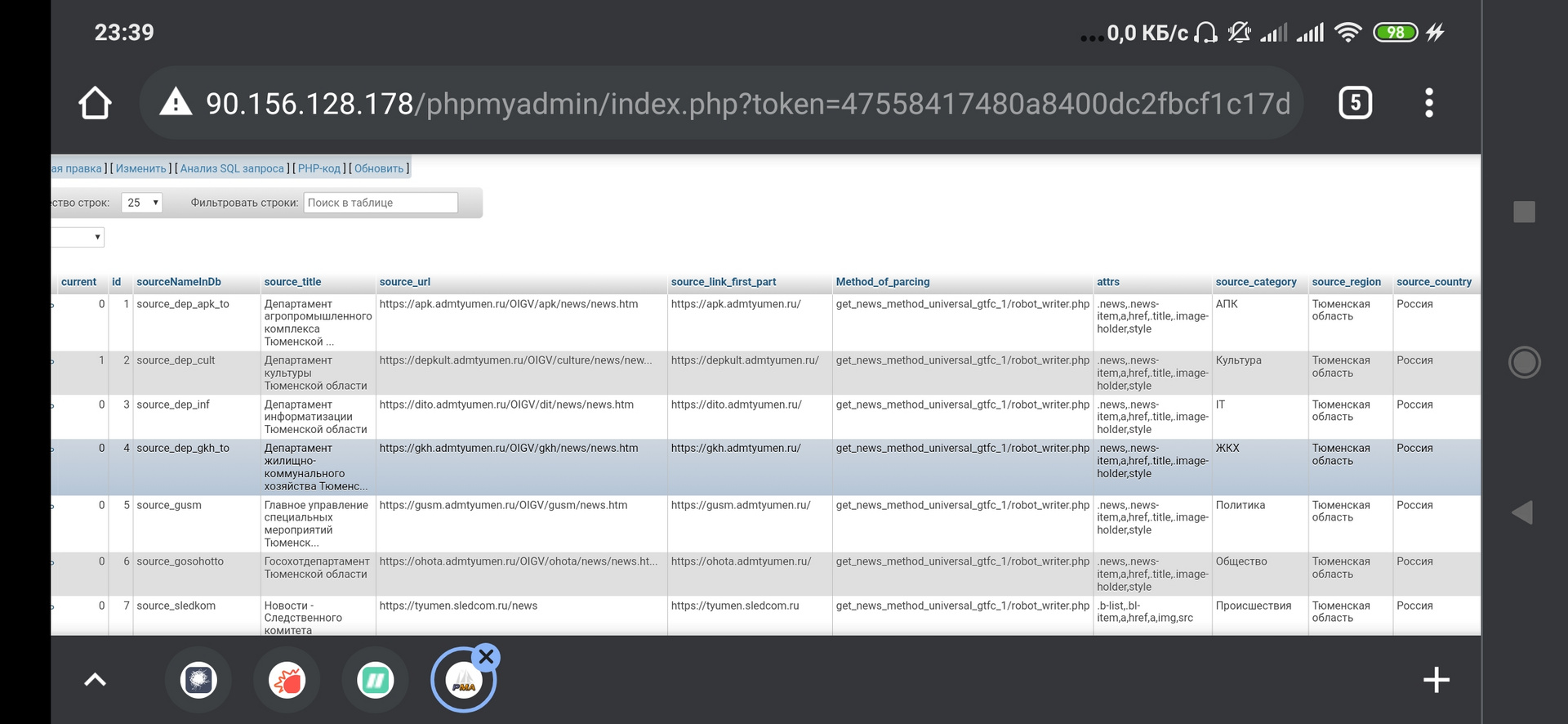
Бд устроена так:
Таб1: список источников. Там - ссылка на страницу с лентой новостей, ссылка на файл с методом парсинга, список селекторов, название таблицы с новостями источника в бд, название категории, к которой относится источник, страна, регион.
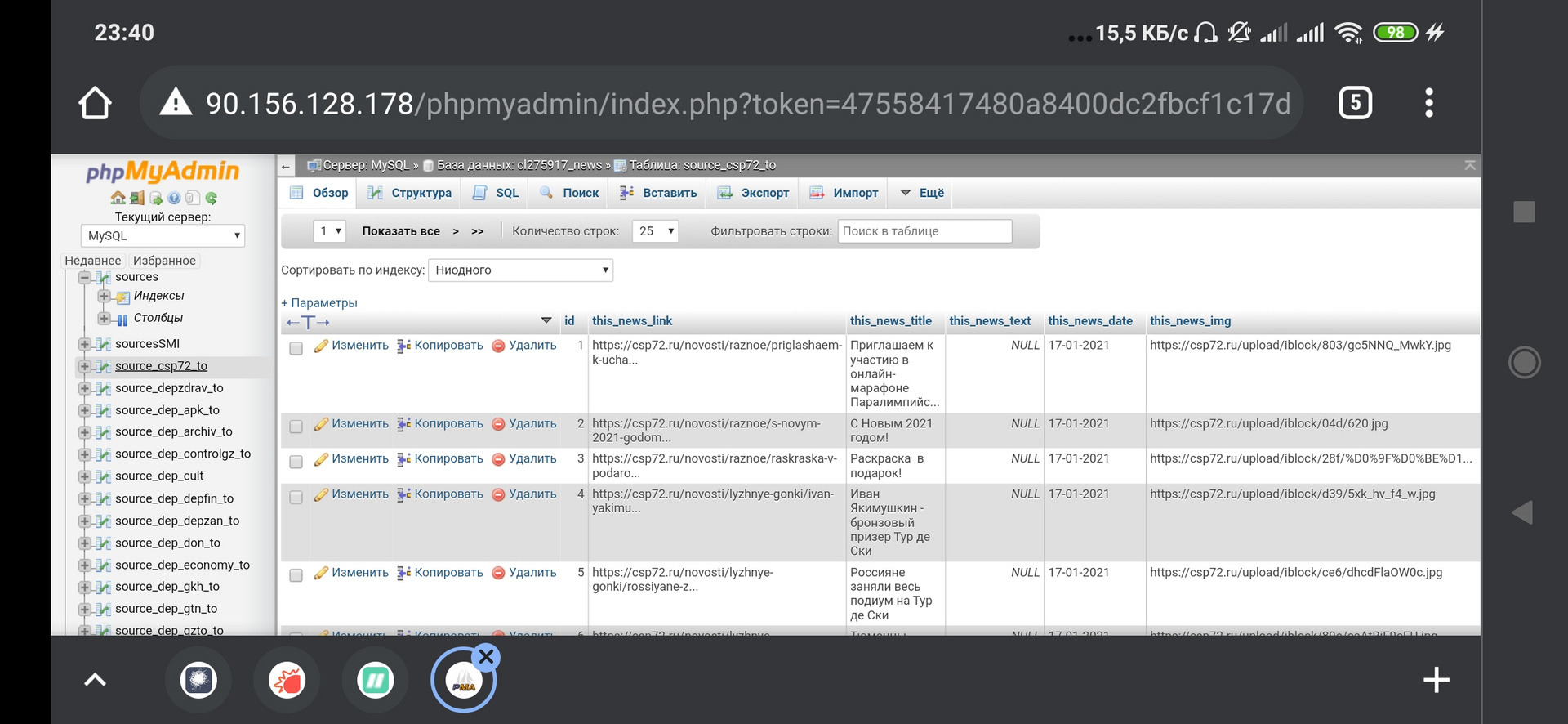
Таб2- ТабN - таблицы с новостями для каждого источника. Их структура одинаковая: заголовок новости, ссылка на страницу с новостью на сайте источника, картинка (если есть), датавремя парсинга.
Логично? Или по-другому должно быть организовано?
Хотя сейчас прикидываю - может и правда все новости пихать в одну таблицу?.. Тогда достать их проще - "селект где `категория` лимит 10"... Но там вперемешку будут все источники и категории... Получается, все юзеры при выборе любых новостей, а также все методы парсинга при записи, будут одну и ту же таблицу долбить...
Короче, мне опыта не хватает, чтобы понять как правильно.
На мой взгляд создавать множество таблиц с одинаковой структурой не правильно. Создайте единую таблицу, добавив колонку с номером источника. В случае большого количества новостей посмотрите на Партиционирование таблиц в mySQL



 Простой
Простой