Всё же можно использовать requests, учитывая что большинство появляющихся сообщений появляются в XHR, позже добавлю примерную инструкцию.
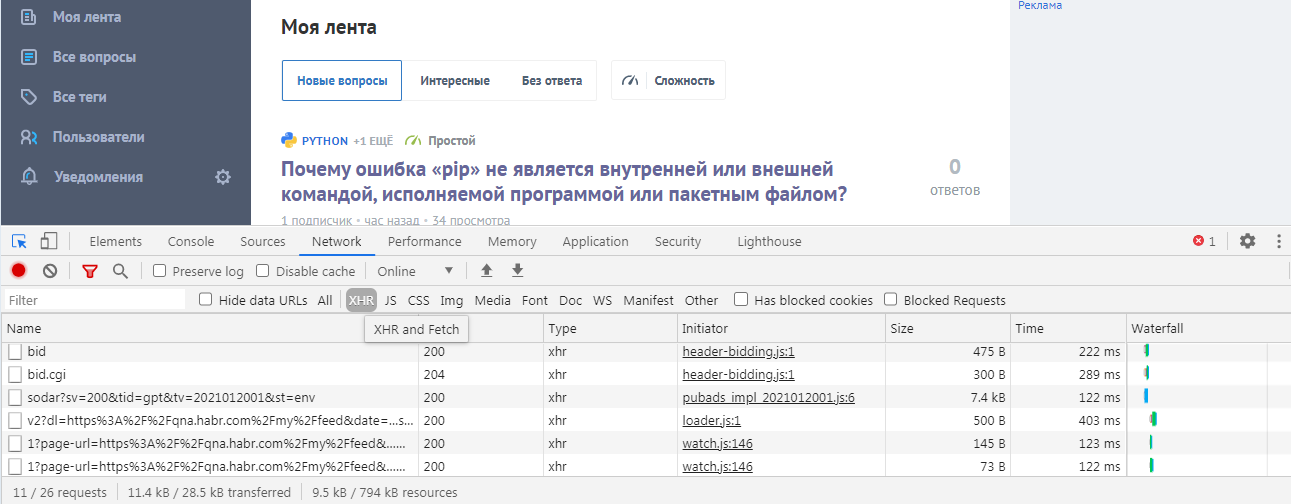
1) Сначала открываем код элемента, заходим в Network, и в XHR, там в основном отображаются подгружаемый текст.
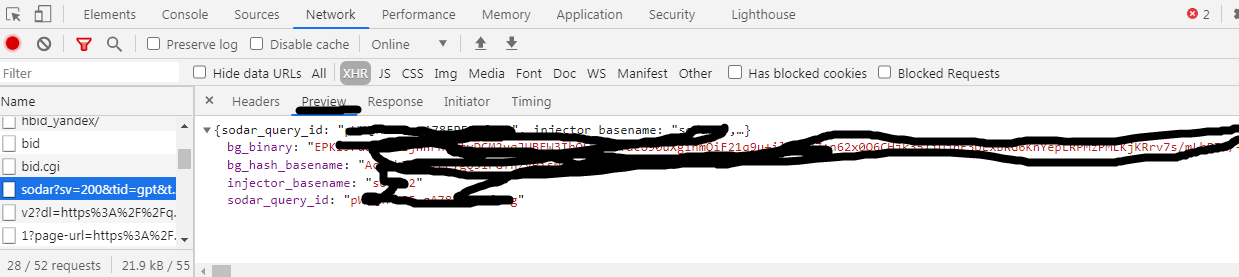
2) Далее можно нажать Preview или Response для ускорения поиска нужного скрипта
3) Когда нашли нужный заходим в Headers и получаем метод(get/post) а так же url для запроса
4) Копируем все (кроме того что идёт с ":" в начале) это будет нашим headers
Перед использованием так же нужно будет отформатировать под словарь, по типу
#accept: */*
head = {'accept': '*/*', ... }
5) Если это Post запрос, то так же достаём параметры из Payload
6) Повторяем запрос, со взятым методом и данными requests.get(url, headers = head)
или же если пост requests.post(url, headers = head, data = Payload)