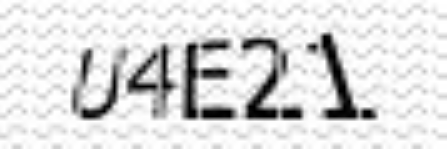Пытаюсь прочитать капчу через tesseract.
Обрабатываю изображение перед отправкой в tesseract.
Результат:
U4E2\.
Т.е. не распознает -
1
Сам код:
$image = new \Imagick('test.jpg');
$image->SharpenImage($radius = 5, $sigma = 1);
$image->gaussianBlurImage($radius = 2, $sigma = 1);
$brightness = 120;
$saturation = 100;
$hue = 60;
$image->modulateImage($brightness, $saturation, $hue);
Подскажите, что еще можно применить, чтобы распознавать с большим шансом?
=========
Согласно документации, можно использовать
whitelist, тем самым ограничивая Tesseract, чтобы он искал только буквы/цифры, а не символы.
Пробовал так(как в документации):
echo (new TesseractOCR('img.png'))
->whitelist(range('a', 'z'), range(0, 9))
->run();
Но почему-то он игнорирует эти требования..