Сформировал скрипт:
from requests_html import HTMLSession
from time import sleep
import random
session = HTMLSession()
# Создаем файл для записи данных
xls_name = f'example-{random.randint(1, 100)}.xls'
with open(xls_name, 'w', encoding='cp1251') as itog:
itog.write('URL\tH1\tTitle\tDescription\n')
# Открываем файл с URl-страниц и получаем дпанный по каждой странице
with open('list-url.txt', 'r') as url_file:
for line in url_file:
url_site = line.strip('\n')
# Делаем запрос по URL
response = session.get(url_site)
h1 = response.html.xpath('//h1/text()')[0]
title = response.html.xpath('//title/text()')[0]
description = response.html.xpath('//meta[@name="description"]/@content')[0]
# Записываем URL, H1, title и description в файл
with open(xls_name, 'a', encoding='cp1251') as itog:
itog.write(f'{url_site}\t{h1}\t{title}\t{description}\n')
print(f'Готово для страницы – {url_site}')
sleep(2)
В файле list-url.txt указываю список URL страниц, с которых хочу получить H1, title и description. Почему-то один URL корректно парсится, а потом вылетает ошибка:

То есть проблема к кодировке при записи? Или в чем-то другом? Операционка Винда 10. Еще уточнение - если здесь:

меняю кодировку на 'utf-8', то информация парсится, но в файле у меня вот так:



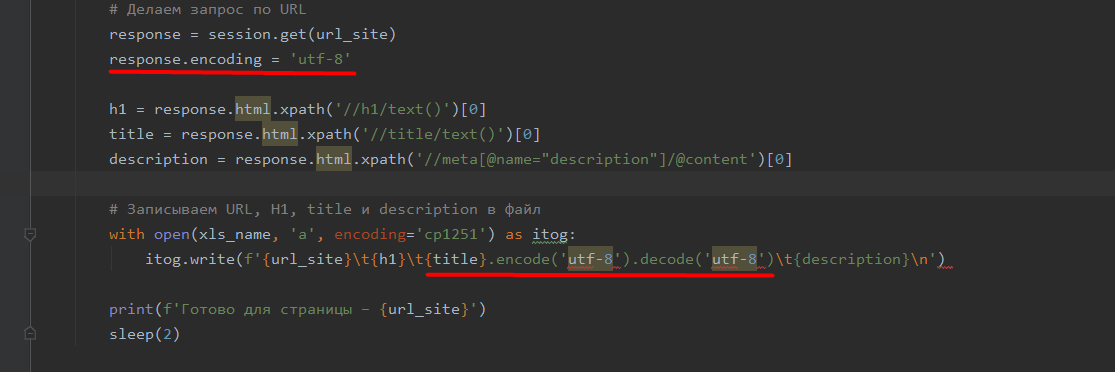
 - в консоли отображается так. Добавил вывод тут:
- в консоли отображается так. Добавил вывод тут:

