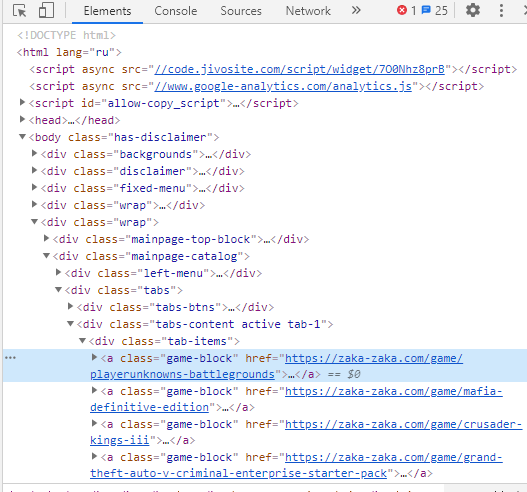
>Не могу запарсить ссылку находящуюся в href
Код программы:
import requests
from bs4 import BeautifulSoup
URL = 'https://zaka-zaka.com/'
HEADERS = {
'user-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'accept': '*/*'}
def get_html(url, params=None):
r = requests.get(url, headers=HEADERS, params=params)
return r
def get_content(html):
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('a' , class_='game-block')
games = []
for item in items:
games.append({
'title': item.find('div' , class_='game-block-name').get_text(strip=True),
'link': item.find('a', class_='game-block') .get('href')
})
print(games)
def parse():
html = get_html(URL)
if html.status_code == 200:
get_content(html.text)
else:
print('Error')
print(html)
parse()
Ошибка из консоли:
Traceback (most recent call last):
File "C:/Users/alady/PycharmProjects/parser/venv/parser228.py", line 38, in
parse()
File "C:/Users/alady/PycharmProjects/parser/venv/parser228.py", line 32, in parse
get_content(html.text)
File "C:/Users/alady/PycharmProjects/parser/venv/parser228.py", line 23, in get_content
'link': item.find('a', class_='game-block') .get('href')
AttributeError: 'NoneType' object has no attribute 'get'
Process finished with exit code 1
Вот код html: