Понимаю, как работает классификатор, разбирающий единичные символы. Тот же рукописный MNIST. Для своей задачи построил примитивную модель, которая прекрасно справляется с моей частной задачей: определённый шрифт, всего 21 символ в алфавите — отдельные символы распознаются на ура.
шрифт и модель
пример моего шрифта, нагенерил картинок для обучения:

Примитивная модель. 21 класс:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28, 1)),
tf.keras.layers.Dense(128,activation='relu'),
tf.keras.layers.Dense(21, activation='softmax')
])
model.compile(
loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['accuracy'],
)
Не могу «въехать», как разбирать последовательность: строку текста.
Длина строки известна и постоянна: 11 символов. Словарь неприменим: это серийные номера.
Примеры
исходный:

обработанный:

сгенеренный:

Из того, что
прочитал, понял, что надо конволюционно «ехать взглядом» вдоль строки маленькими шагами, на каждом пытаясь опознать символ «в кадре».
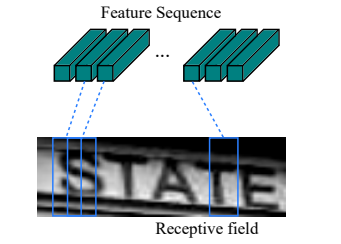
Не могу понять, как из набора выходных предположений строить окончательную строку. Ведь на нескольких соседних кадрах символ может повторяться. Между символами могут с низкой уверенностью предполагаться какие-то левые варианты.
Пишут про CTC loss function (Connectionist Temporal Classification), но там обучение на большом объёме примеров. А у меня полный перебор всех комбинаций алфавита.
Хочу реализовать это самостоятельно, без OpenCV, Tesseract и Keras-OCR. Только TensorFlow, Keras,
хард-софткор.


 Простой
Простой
 Простой
Простой
 Средний
Средний


