Здравствуйте, сразу две проблемы.
1. По идее в конечной таблице должно быть 2 колонки (caption, url), но вопреки ожиданиям запись идет в одну.
caption и url записываются вмечте, через запятую. Каждая вторая строчка пропускается.
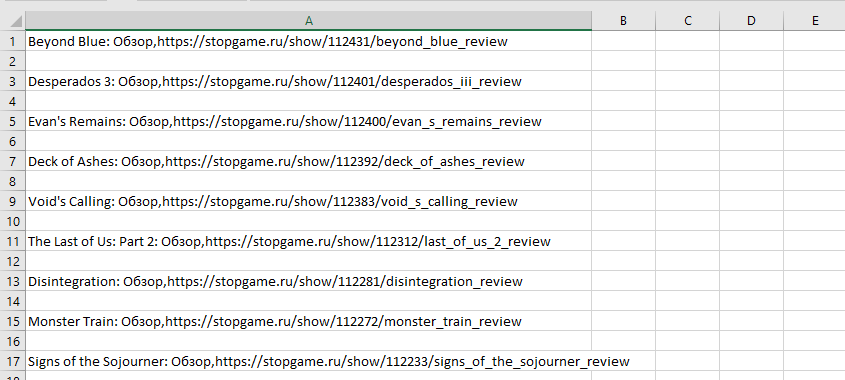
2. Судя по всему парсинг идет до заголовка "Astérix & Obélix XXL 3: The Crystal Menhir: Обзор" и выдает:
Traceback (most recent call last):
File "parser_stopgame_v2.py", line 56, in
main()
File "parser_stopgame_v2.py", line 52, in main
get_page_data(html)
File "parser_stopgame_v2.py", line 39, in get_page_data
write_csv(data)
File "parser_stopgame_v2.py", line 20, in write_csv
data['url']) )
File "C:\Users\User\AppData\Local\Programs\Python\Python37\lib\encodings\cp1251.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_table)[0]
UnicodeEncodeError: 'charmap' codec can't encode character '\xe9' in position 3: character maps to
Как я понимаю, дело в символе "é". Как это испраавить?
from bs4 import BeautifulSoup as BS
import requests
import csv
def get_html(url):
r = requests.get(url)
return(r.text)
def get_total_pages(html):
soup = BS(html, 'lxml')
pages = soup.find('div', class_='pagination').find_all('a', class_="item")[-1].find('span').text
return int(pages)
def write_csv(data):
with open('stopgame.csv', 'a') as f:
writer = csv.writer(f)
writer.writerow( (data['caption'],
data['url']) )
def get_page_data(html):
soup = BS(html, 'lxml')
games = soup.find('div', class_='tiles').find_all('div', class_='caption')
for game in games:
try:
caption = game.find('a').text
except:
caption = ''
try:
url = 'https://stopgame.ru' + game.find('a').get('href')
except:
url = ''
data = {'caption': caption,
'url': url}
write_csv(data)
def main():
url = 'https://stopgame.ru/review/new/p'
total_pages = get_total_pages(get_html(url))
for i in range(1, total_pages + 1):
url_gen = url + str(i)
#print(url_gen)
html = get_html(url_gen)
#print(get_page_data(html))
get_page_data(html)
if __name__ == '__main__':
main()

