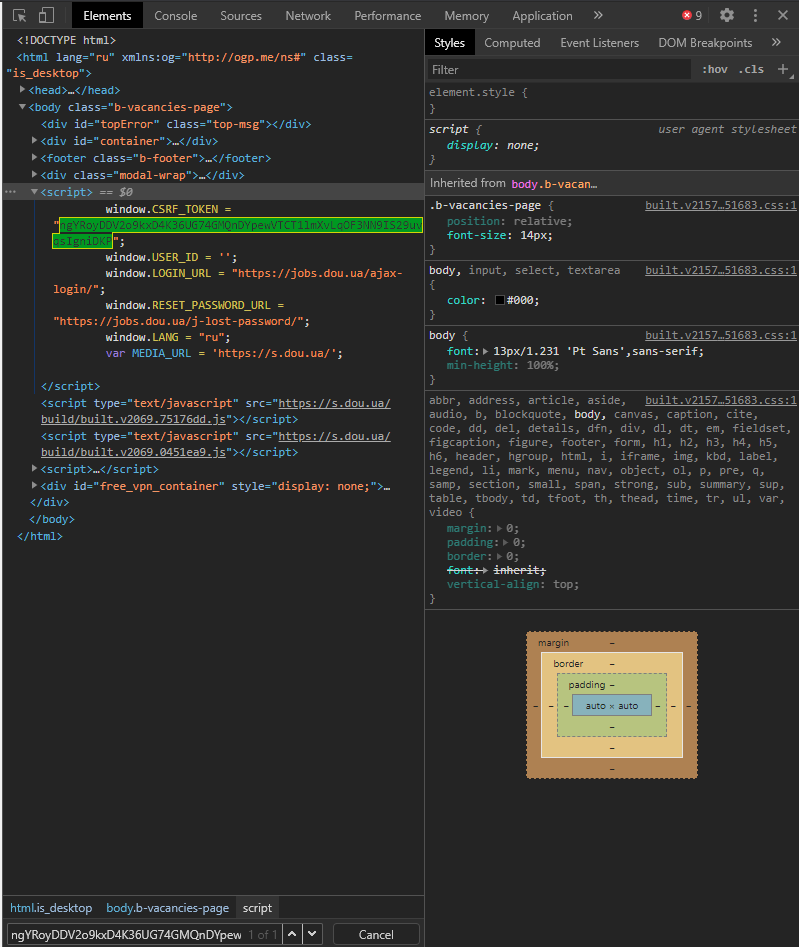
Решил попробовать реализовать парсер вакансий. Сайт выдает только 20 ссылок, дальше кнопка "Больше".
Через вкладку "Network" посмотрел что отправляет запрос. Костыльно вытащил CSRF_TOKEN (вытаскивает раз через раз) и сделал запрос, получаю статус-код 403.
Сайт :
https://jobs.dou.ua/vacancies/?category=Ruby
Код:
import requests
from bs4 import BeautifulSoup
HEADERS = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
URL = "https://jobs.dou.ua/vacancies/?category=Ruby"
session = requests.Session()
def get_html(url):
r = session.get(url, headers=HEADERS)
return r
def get_links(response):
if response.status_code == 200:
html = BeautifulSoup(response.text, "html.parser")
lis = html.find_all('li', class_="l-vacancy")
# Количество вакансий до нажатия
print(len(lis))
# Костыльно достаю csrf
script = str(html.select('script')[5])
csrf = str(script[32:32+64])
print(script)
print(csrf)
load_data = {
'csrfmiddlewaretoken': csrf,
'count': 20}
response = session.post('https://jobs.dou.ua/vacancies/xhr-load/?category=Ruby', data=load_data)
print(response.status_code)
html = BeautifulSoup(response.text, "html.parser")
lis = html.find_all('li', class_="l-vacancy")
# Количество вакансий после нажатия
print(len(lis))
else:
return 'Connection error!'
get_links(get_html(URL))


 Средний
Средний
 Сложный
Сложный