В python рег. выражения работают правильно, например:
import re
s = '''Если ты хочешь построить корабль, не надо созывать людей, планировать, делить работу, доставать инструменты.
Надо заразить людей стремлением к бесконечному морю. Тогда они сами построят корабль.'''
pattern = r'\w+'
match = re.findall(pattern, s)
if match:
print(match)
Выводит ожидаемо:
['Если', 'ты', 'хочешь', 'построить', 'корабль', 'не', 'надо', 'созывать', 'людей', 'планировать', 'делить', 'работу', 'доставать', 'инструменты', 'Надо', 'заразить', 'людей', 'стремлением', 'к', 'бесконечному', 'морю', 'Тогда', 'они', 'сами', 'построят', 'корабль']
Делаю то же самое в программе, на выходе черт знает что:
\w [a-z0-9] Буквы и цифры
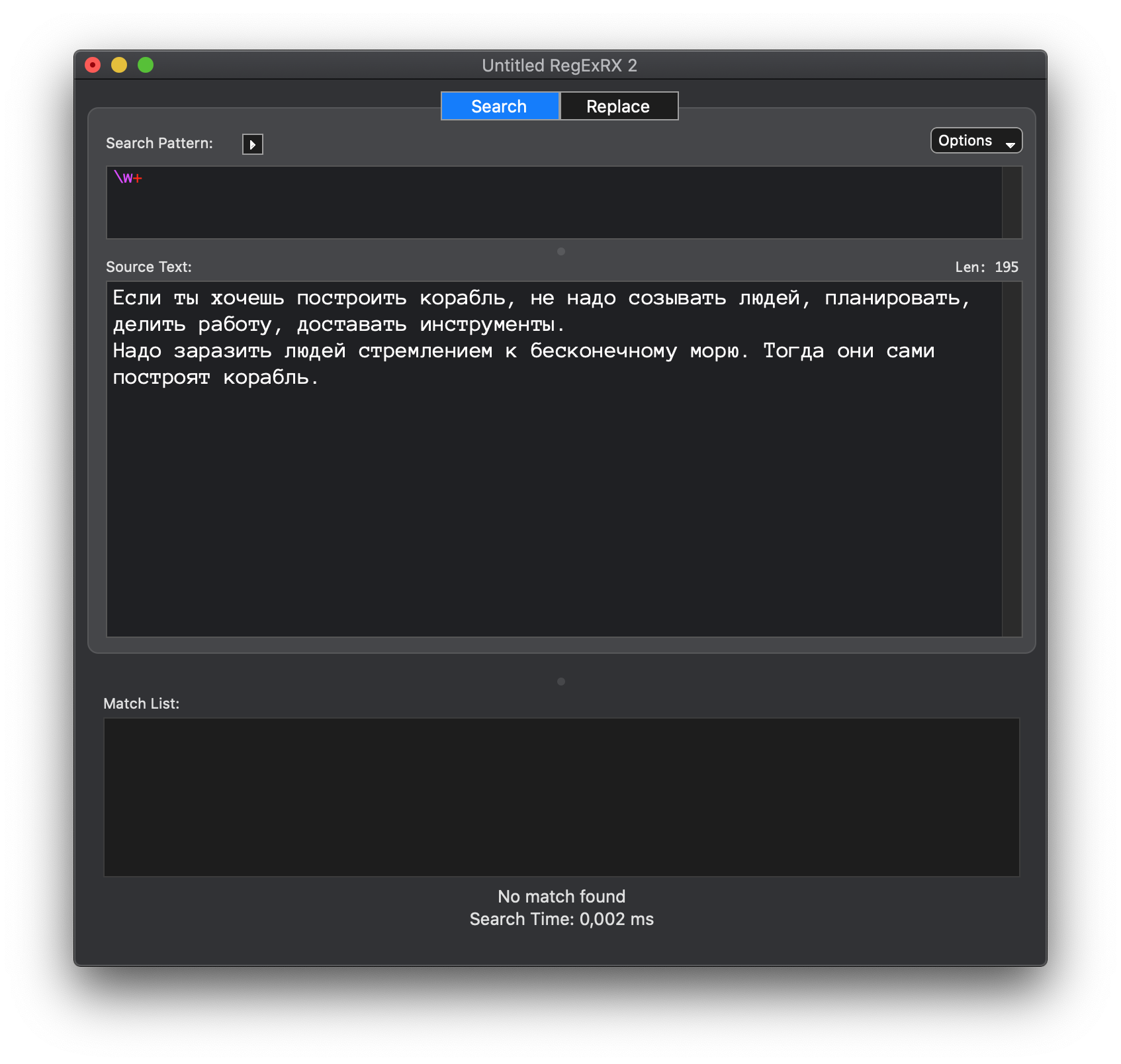
Вообще не видит ни букв, ни слов.
Меняю на большую W
\W [^a-z0-9] Кроме букв и цифр
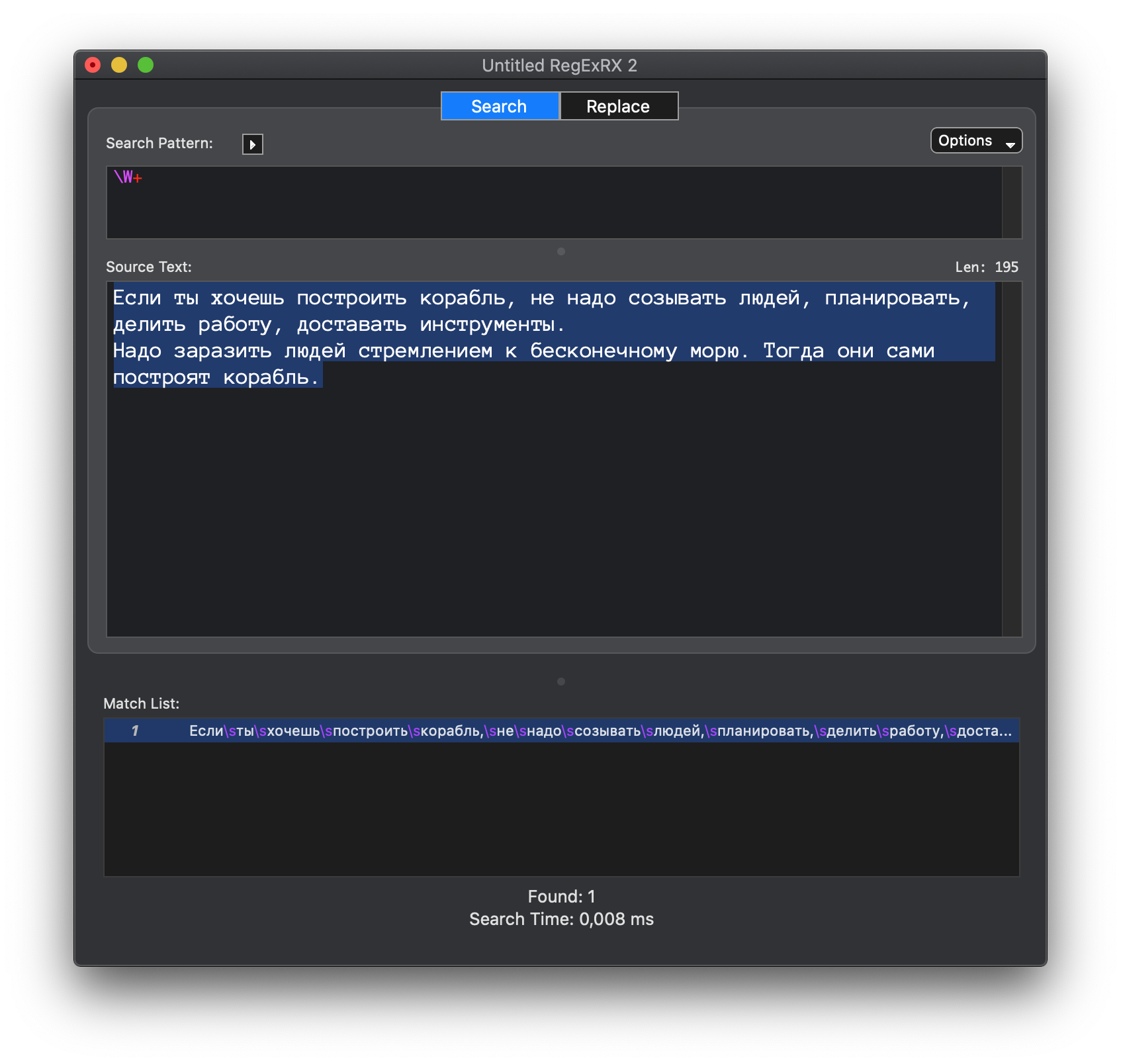
А здесь видит и буквы и цифры. Что не так?



 Простой
Простой