import requests
from bs4 import BeautifulSoup
import csv
URL ='https://auto.ru/krasnodar/cars/bmw/x5/all/?sort=fresh_relevance_1-desc'
HEADERS = {'user-agent':'Mozilla / 5.0 (Windows NT 10.0; WOW64) AppleWebKit / 537.36 (KHTML, like Gecko) Chrome / 80.0.3987.132 YaBrowser / 20.3.2.242 Yowser / 2.5 Safari / 537.36'}
HOST ='https://auto.ru'
FILE = 'cars.csv'
def get_html (url, params=None):
r = requests.get(url,headers=HEADERS, params = params)
return r
def get_pages_count(html):
soup = BeautifulSoup(html, 'html.parser')
pagination = soup.find_all('a', class_='Button Button_color_whiteHoverBlue Button_size_s Button_type_link Button_width_default ListingPagination-module__page')
if pagination:
return int(pagination[-1].get_text())
else:
return 1
def get_content(html):
soup = BeautifulSoup(html,'html.parser')
items = soup.find_all('div', class_='ListingItem-module__main')
cars = []
for item in items:
cars.append({
'title': item.find('h3', class_='ListingItemTitle-module__container ListingItem-module__title').get_text(),
'link': HOST + item.find('a', class_='Link ListingItemTitle-module__link').get('href'),
'price': item.find('div', class_='ListingItemPrice-module__content').get_text(),
})
return cars
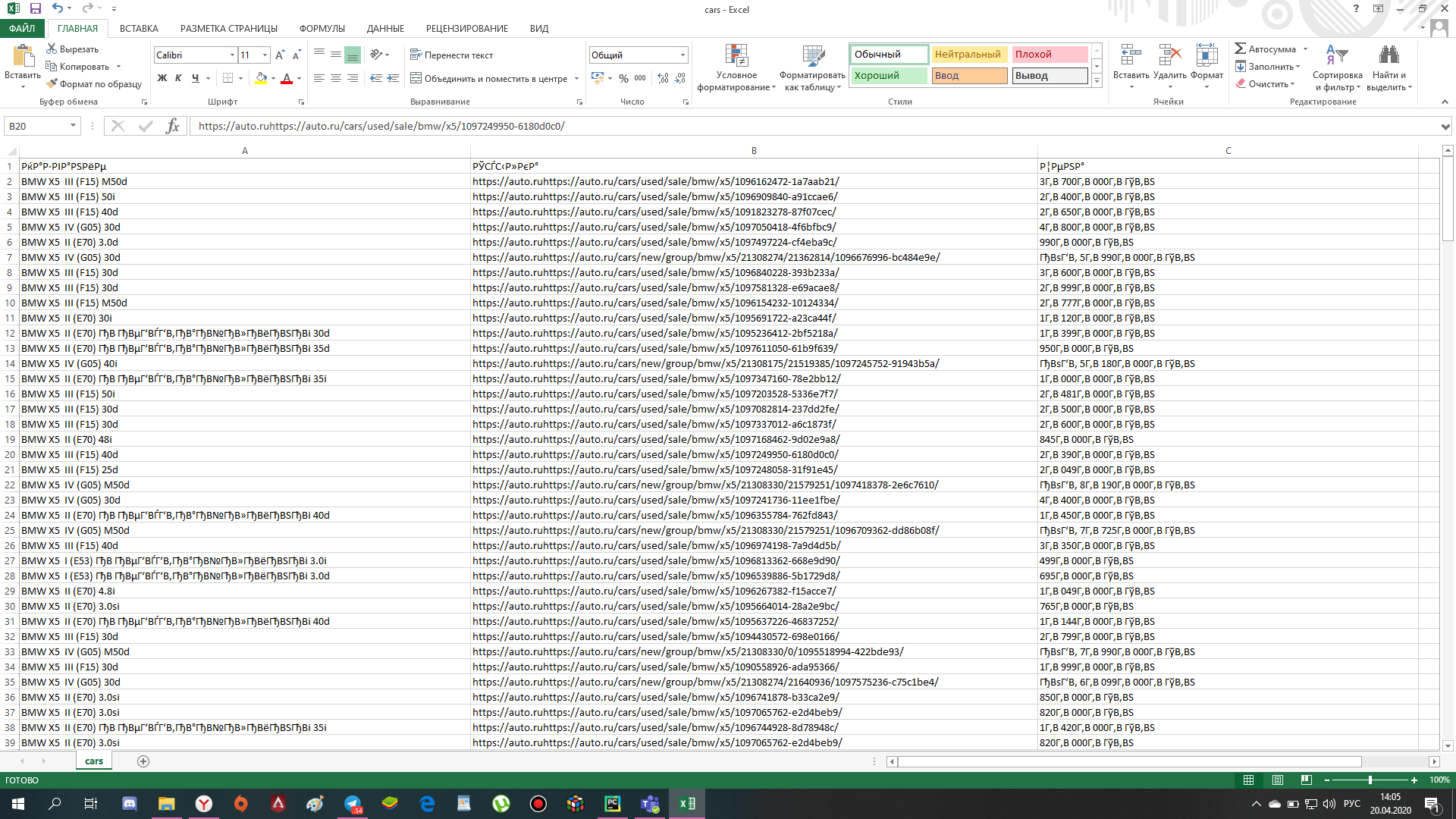
def save_file(items,path):
with open(path, 'w', newline='') as file:
writer = csv.writer(file, delimiter=';')
writer.writerow(['Название', 'Ссылка','Цена'])
for item in items:
writer.writerow([item['title'], item['link'], item['price']])
def parse():
html = get_html(URL)
if html.status_code == 200:
cars=[]
pages_count = get_pages_count(html.text)
for page in range(1, pages_count+1):
print(f'Парсинг страницы {page} из {pages_count}...')
html = get_html(URL, params={'page': page})
cars.extend(get_content(html.text))
save_file(cars,FILE )
print(f'Получено {len(cars)} автомобилей')
else:
print('Ошибка с числом 200')
parse()