Коллеги, доброго времени суток!
Интересует следующее:
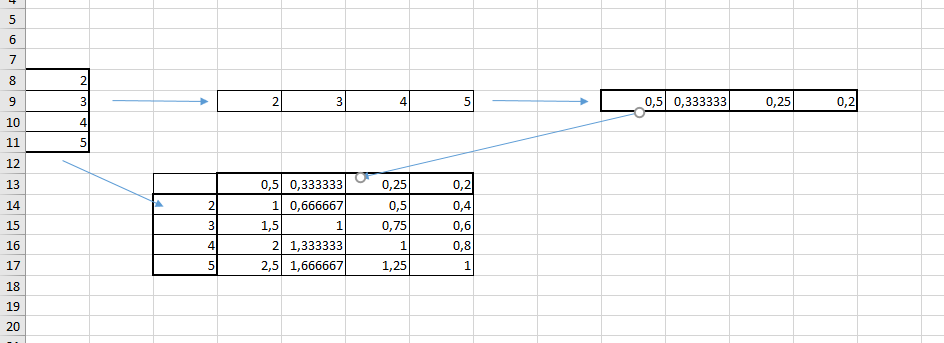
Я из БД получаю df размером 10 млн строк на n столбцов;
Дальше выбираю из этого df один столбец;
Делаю его копию состоящую из обратных значений;
Полученную копию делаю строкой;
Дальше умножаю матричным способом через np.dot()столбец на сформированную строку.
------------------------------------------------------------------------------------------------------------------
Chunk - первый способ ускорения, чтобы умножать по частям - матрицами размером chunk_size на 10 млн
Есть еще варианты как это можно было бы ускорить? Возможно есть какое то оптимальное значение параметра chunk?
chunk_size = 25
Матрица столбец, выделенная из изначального столбца размером 10 млн, размером chunk умножается на матрицу строку размером 10 млн - в итоге получается матрица размером chunk на 10 млн
PyTuch, тогда не пойму при чем здесь скалярное произведение (dot). Это же обычное матричное умножение.. вектора-столбца на вектор строку с результатом - матрицей...
Можно пример какой-нибудь небольшой.. хоть из 3-4 элементов?
Чтобы из столбца брать не все 10 млн а только часть и в цикле прозожусь по столбцу обрабатывая матрицу размером chunk на 10 млн (размер chunk определяется способностями компьютера)
И вопрос в том - можно ли сделал код лучше (например Возможно есть оптимальное значение chunk то есть не чем больше тем лучше )