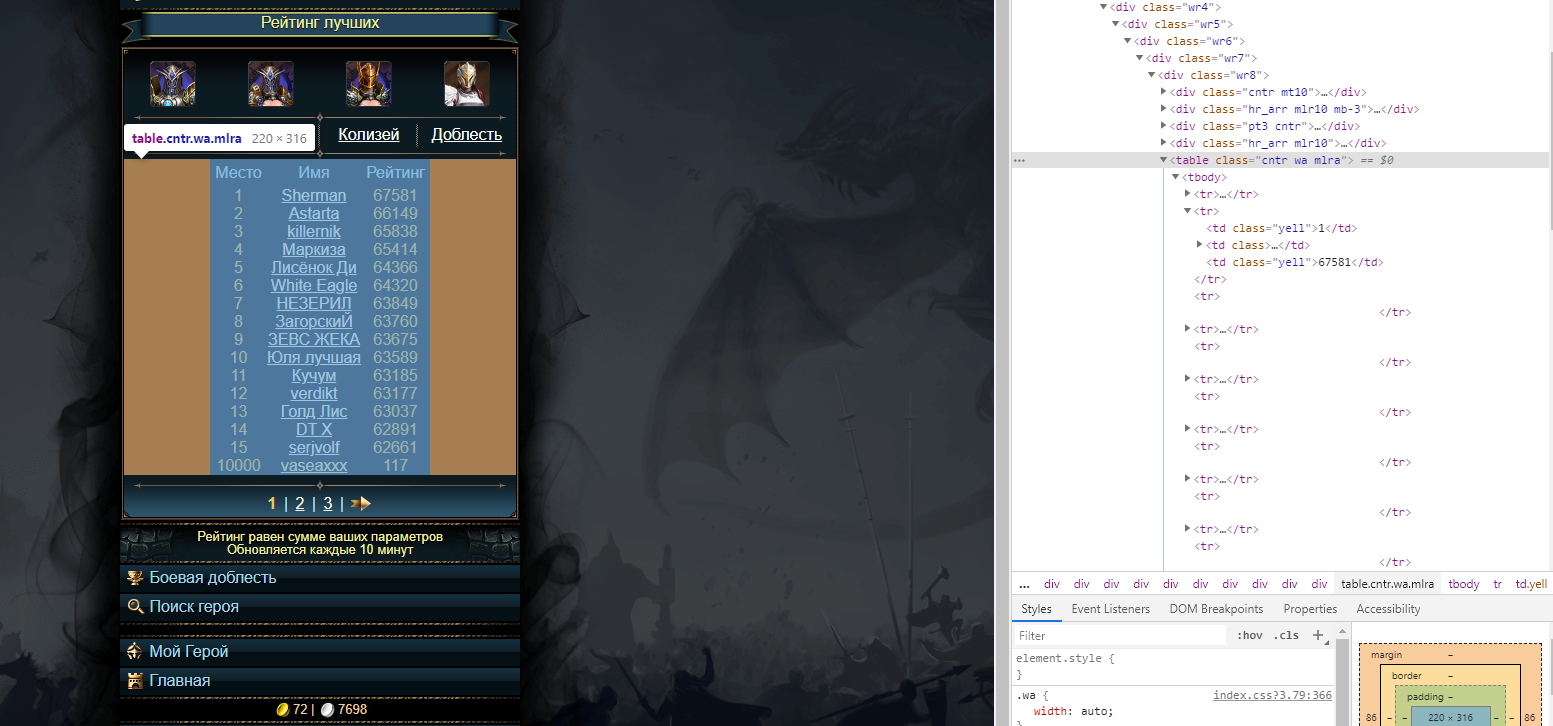
1) Вы ищете таблиц
ы с классом 'cntr wa mlra', а нужно таблиц
у.
2) Уже в найденной таблице искать (как вариант) все теги 'a' с классом 'lwhite'
table = soup.find('table', {"class": "cntr wa mlra"})
names = table.find_all('a',class_='lwhite')
for name in names:
nick = name.text
print(nick)
3) Вы их уже
задолбали, они поставили хитрую защиту от таких скриптов. Нужно делать задержки при отправке запросов.
Насчет защиты - там теперь при авторизации нужно передавать еще один параметр(с пустым значением) с рамдомным именем. Но просто перед авторизацией сделать get запрос и вытащить данный параметр просто так не получится, там немного хитрее всё это сделано.
Рабочий код(куки скопировал из браузера):
import requests
from bs4 import BeautifulSoup
from lxml import html
import time
cookies = {'PHPSESSID':'c3a1cde86c8c8c9f0e3877403ad4935e.1585230344.54638591'}
headers = {'user-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.0'}
for i in range(1,6):
mrush = open('ParsNick.txt','a')
html_text = requests.get(f"http://mrush.mobi/best?pvp=0&page={i}",cookies=cookies,headers=headers).text
soup = BeautifulSoup(html_text, 'html.parser')
table = soup.find('table', {"class": "cntr wa mlra"})
names = table.find_all('a',class_='lwhite')
for name in names:
nick = name.text
print(nick)
mrush.write(nick+'\n')
mrush.close()
time.sleep(1)