Образец файла, с которым предстоит работа (расположение таблицы, а также размеры ячеек у всех одинаковое, кроме тех случаев, когда ширина ячейки мб шире в два-тра раза, в отличие от стандартной)
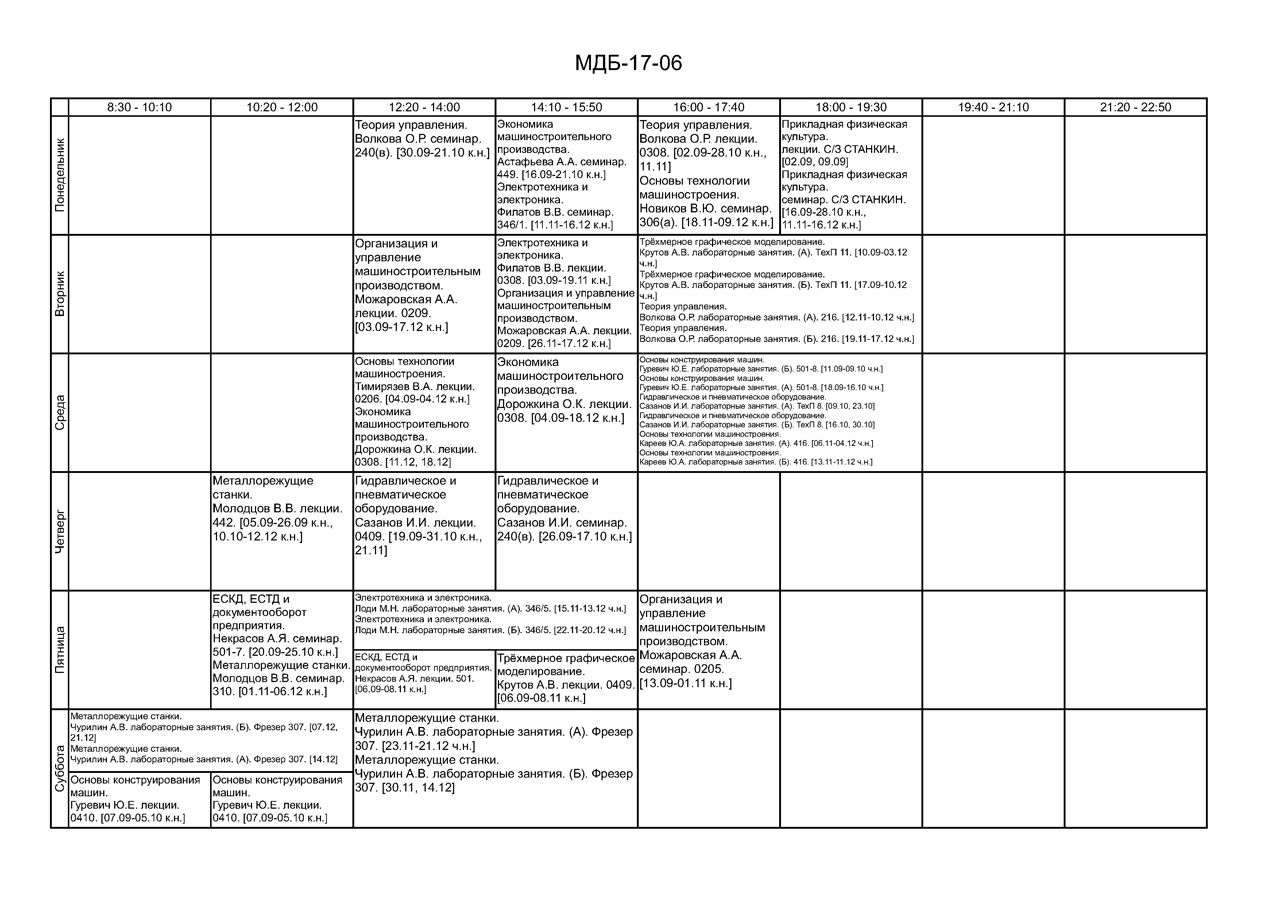
Представление работы с ячейками

Основная суть вопроса, какие вещи необходимо уяснить, какие книги посоветуете, для того, чтобы решить такую задачу.
Пояснение к работе:
Написание программы, которая бы преобразовывала такую картинку с расписанием, в json файл, с которыми можно было бы производить отдельные операции
Образец .json файла:
"title" "Трёхмерное графическое моделирование"
"lecturer" "Крутов А.В."
"type" "Laboratory"
"subgroup" "(А)"
"classroom" "ТехП 11"
"start" "16:00"
"end" "19:30"
"frequency" "throught"
"date" "2019.09.10-2019.12.03"
Как я представляю решение этой задачи:
1. На картинке распознаем таблицу, проводим прямые линии, если не ошибаюсь Canny метод может искать границы объектов, первая строка и первый столбец кстати вообще не нужны (время зависит от ширины и местоположения ячейки, как бы это по странному не звучало, а какой день недели вообще не играет роли)
2. Смотрим в каких ближайших точках идет пересечение линий, в соответствии с ними мы можем выбрать прямоугольную область, с которой мы можем производить распознавание текста, с последующим преобразованием в json файл, причем при работе с текстом тоже есть ряд вопросов, как его правильно классифицировать, так как в табличке мб несколько записей занятий, даты могут быть указаны разные для нескольких промежутков, какая-то информация может быть не совсем типовая, как у др предметов и т.д.
3. В соответствии с расположением этой прямоугольной области, определяем какое время должно быть присвоено всем проводимым занятиям в данной ячейке
4. Самое распознавание текста и классификация в зависимости от данных
5. Подходим к следующей прямоугольной области (слева направо и сверху вниз)
Опыт программирования небольшой, из языков знаю только C++, базовые вещи из ОПП знаю (хотя все субъективно)), как я понимаю библиотека OpenCV C++ очень поможет мне в решении этой задачи, ещё насколько понимаю, что распознавать текст придется с помощью другой библиотеки (на базе OCR), плюс ещё скорее всего будут какие-то сюрпризы




