Есть веб-приложение. У него есть потребность по изображению получить некие данные. В формировании данных участвуют три сервиса.
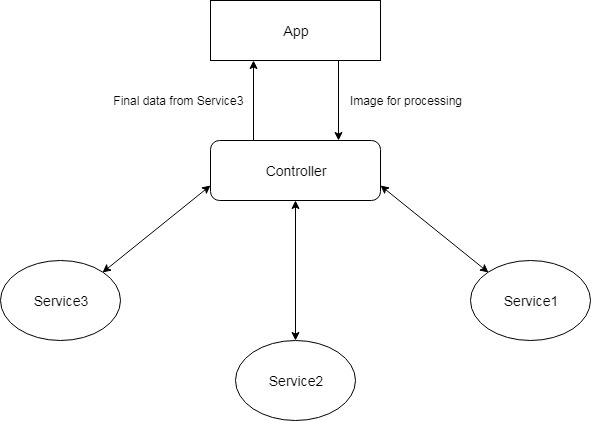
Изображение подаётся на вход Service1. Он возвращает данные, которые подаются на вход Service2. Результат Service2 подаётся на вход Service3. И результат Service3 отдаётся клиенту.
Так как сервисы весьма разрозненные со своим окружением, то решено было выделить их в отдельные контейнеры.
Вопрос - как правильно организовать передачу данных в таком случае?
Как я понимаю, нужен какой-то контроллер, как указал на изображении, который будет передавать данные между сервисами и возвращать результат в основное приложение.
Все узлы (приложение, контроллер, сервисы) вынести в контейнеры.
Передачу данных между всеми узлами выполнять через HTTP-запросы (в частности, изображение передавать через base64).
Так как кол-во нод любого сервиса может быть разное количество, то получается нужен ещё балансировщик для контроллера, который будет помогать определять случайную ноду сервиса.
Вышеописанное - построение "велосипеда" и есть какие-то стандартные техники?
Или же есть статья, описывающая подобное (передача данных, контроллер для сервисов)?




