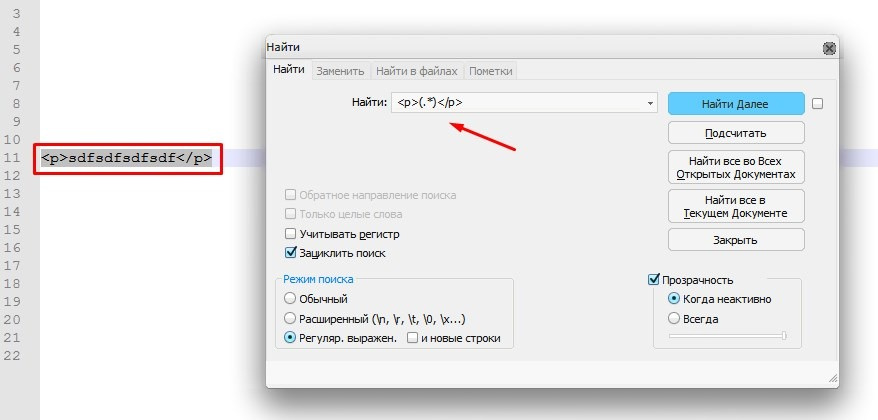
<тэг>.*</тэг> и выделялся текст внутри указанных тэгов. Но у меня почему то выделяется всё целиком, вместе с тэгами.  Простой
Простой