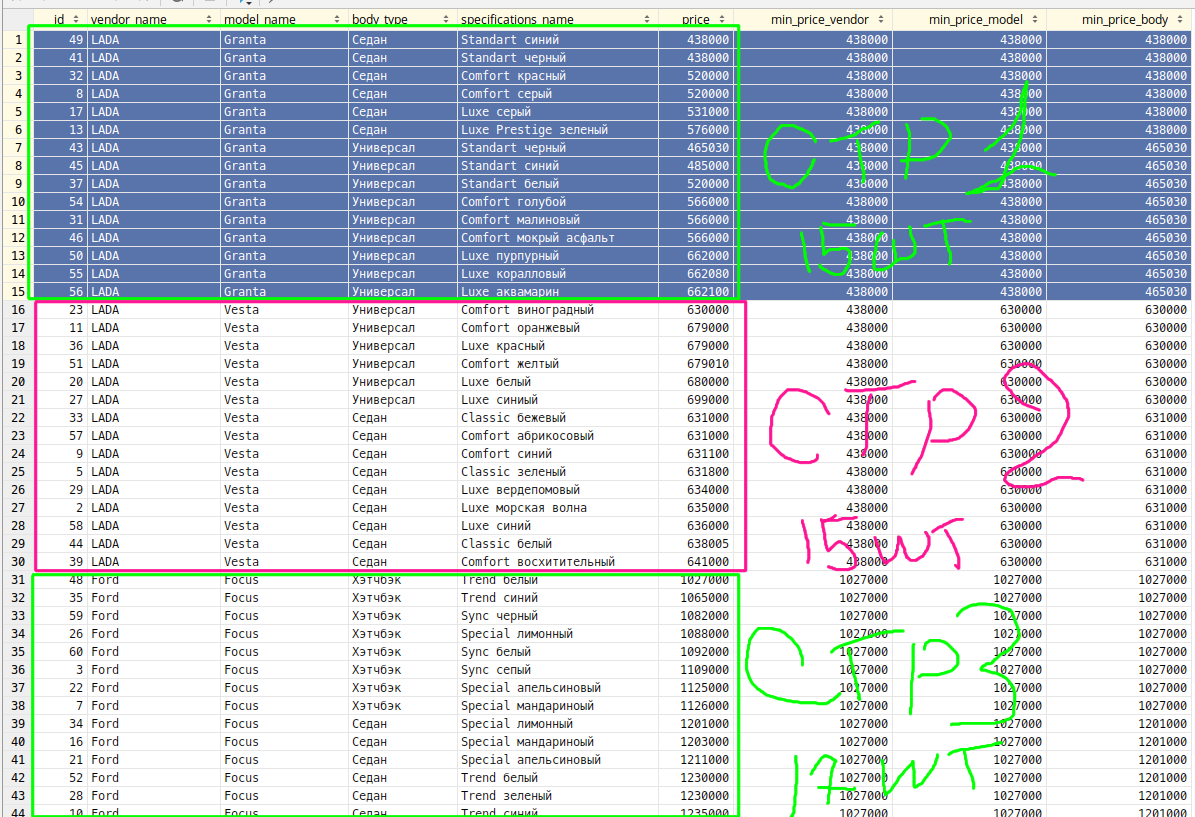
INSERT INTO car(vendor_name, model_name, body_type, specifications_name, price) VALUES
('Peugeot', '408', 'Седан', 'Allure 115лс бежевый', 1144000),
('LADA', 'Vesta', 'Седан', 'Luxe морская волна', 635000),
('Ford', 'Focus', 'Хэтчбэк', 'Sync сепый', 1109000),
('Ford', 'Focus', 'Седан', 'Sync белый', 1250800),
('LADA', 'Vesta', 'Седан', 'Сlassic зеленый', 631800),
('Audi', 'A4', 'Универсал', 'Желтый', 2900000),
('Ford', 'Focus', 'Хэтчбэк', 'Special мандариноый', 1126000),
('LADA', 'Granta', 'Седан', 'Comfort серый', 520000),
('LADA', 'Vesta', 'Седан', 'Сomfort синий', 631100),
('Ford', 'Focus', 'Седан', 'Trend синий', 1235000),
('LADA', 'Vesta', 'Универсал', 'Comfort оранжевый', 679000),
('Audi', 'A4', 'Седан', 'Желтый', 2000000),
('LADA', 'Granta', 'Седан', 'Luxe Prestige зеленый', 576000),
('Peugeot', '408', 'Седан', 'Active красный', 1177000),
('Audi', 'A4', 'Седан', 'Желтый', 2000000),
('Ford', 'Focus', 'Седан', 'Special мандариноый', 1203000),
('LADA', 'Granta', 'Седан', 'Luxe серый', 531000),
('Peugeot', '408', 'Седан', 'Allure 150лс белый', 1122000),
('Audi', 'A4', 'Универсал', 'Серый', 2900000),
('LADA', 'Vesta', 'Универсал', 'Luxe белый', 680000),
('Ford', 'Focus', 'Седан', 'Special апельсиновый', 1211000),
('Ford', 'Focus', 'Хэтчбэк', 'Special апельсиновый', 1125000),
('LADA', 'Vesta', 'Универсал', 'Comfort виноградный', 630000),
('Peugeot', '408', 'Седан', 'Allure 150лс пурпурный', 1125000),
('Audi', 'A3', 'Хетчбек', 'Белый', 2000000),
('Ford', 'Focus', 'Хэтчбэк', 'Special лимонный', 1088000),
('LADA', 'Vesta', 'Универсал', 'Luxe синиый', 699000),
('Ford', 'Focus', 'Седан', 'Trend зеленый', 1230000),
('LADA', 'Vesta', 'Седан', 'Luxe вердепомовый', 634000),
('Ford', 'Focus', 'Седан', 'Sync сепый', 1260000),
('LADA', 'Granta', 'Универсал', 'Comfort малиновый', 566000),
('LADA', 'Granta', 'Седан', 'Comfort красный', 520000),
('LADA', 'Vesta', 'Седан', 'Сlassic бежевый', 631000),
('Ford', 'Focus', 'Седан', 'Special лимонный', 1201000),
('Ford', 'Focus', 'Хэтчбэк', 'Trend синий', 1065000),
('LADA', 'Vesta', 'Универсал', 'Luxe красный', 679000),
('LADA', 'Granta', 'Универсал', 'Standart белый', 520000),
('Audi', 'A4', 'Универсал', 'Черный', 3000000),
('LADA', 'Vesta', 'Седан', 'Сomfort восхитительный', 641000),
('Ford', 'Focus', 'Седан', 'Sync черный', 1250000),
('LADA', 'Granta', 'Седан', 'Standart черный', 438000),
('Audi', 'A3', 'Хетчбек', 'Желтый', 2000000),
('LADA', 'Granta', 'Универсал', 'Standart черный', 465030),
('LADA', 'Vesta', 'Седан', 'Сlassic белый', 638005),
('LADA', 'Granta', 'Универсал', 'Standart синий', 485000),
('LADA', 'Granta', 'Универсал', 'Comfort мокрый асфальт', 566000),
('Audi', 'A4', 'Универсал', 'Белый', 2900000),
('Ford', 'Focus', 'Хэтчбэк', 'Trend белый', 1027000),
('LADA', 'Granta', 'Седан', 'Standart синий', 438000),
('LADA', 'Granta', 'Универсал', 'Luxe пурпурный', 662000),
('LADA', 'Vesta', 'Универсал', 'Comfort желтый', 679010),
('Ford', 'Focus', 'Седан', 'Trend белый', 1230000),
('Audi', 'A3', 'Хетчбек', 'Черный', 2000000),
('LADA', 'Granta', 'Универсал', 'Comfort голубой', 566000),
('LADA', 'Granta', 'Универсал', 'Luxe коралловый', 662080),
('LADA', 'Granta', 'Универсал', 'Luxe аквамарин', 662100),
('LADA', 'Vesta', 'Седан', 'Сomfort абрикосовый', 631000),
('LADA', 'Vesta', 'Седан', 'Luxe синий', 636000),
('Ford', 'Focus', 'Хэтчбэк', 'Sync черный', 1082000),
('Ford', 'Focus', 'Хэтчбэк', 'Sync белый', 1092000)
;


 Средний
Средний
 Простой
Простой

