Собственно имеется следующая ситуация
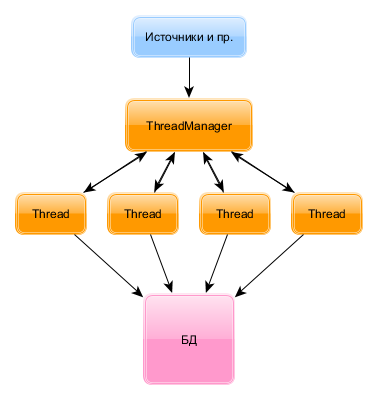
Из различных этапов обработки поступают данные на менеджер потоков - в нем есть глобальная куча входных данных.
Во время начала обработки создаются N потоков парсинга данных и формирования пачек запросов. Каждый поток, если он обработал имевшиеся у него данные, запрашивает новую пачку у менеджера потоков. Тот в свою очередь скидывает запросившему потоку всю имеющуюся кучу входных данных. При накоплении определенного количества данных, либо по времени простоя без входных данных - поток начинает процедуру отправки подготовленных пачек запросов в БД.
Сейчас это работает, делалось путем проб и ошибок. Охота узнать как это можно оптимизировать и где можно об этом почитать.
Заранее благодарю!
З.Ы.: если кто-нибудь поделится своим опытом создания подобных систем, буду примного благодарен! ;)



