Проектирую базу данных для одного проекта. Ключевая таблица проекта, это таблица, в которой следующие поля:
1. Номер
2. ФИО Пациента
3. ФИО Врача
4. Дата начала болезни
5. Дата конца болезни
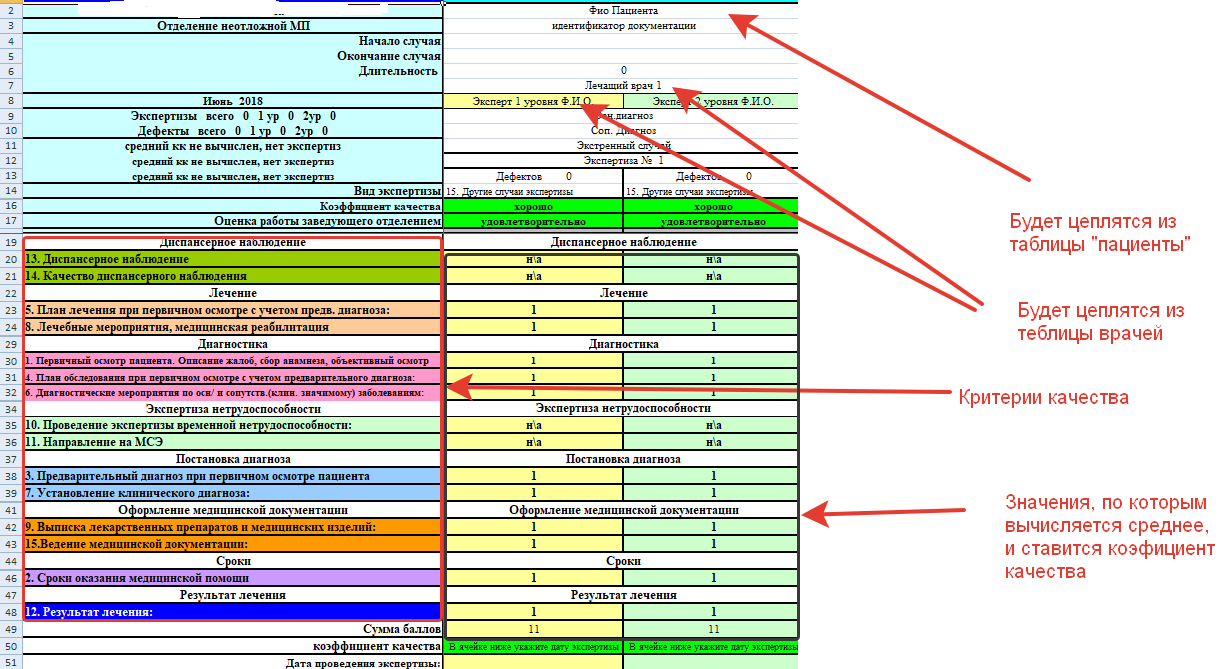
6. Критерий оценки оказания медицинской помощи №1
7. Критерий оценки оказания медицинской помощи №2
8. Критерий оценки оказания медицинской помощи №3
9. Критерий оценки оказания медицинской помощи №4
10. Критерий оценки оказания медицинской помощи №5
11. Критерий оценки оказания медицинской помощи №6
Каждый из полей "Критерий оценки ..... Х" принимает значения: 0, 0.5, 1. Но проблема в том, что критерии оценки динамичны и могут менятся. И что бы предусмотреть возможность хоть какого маштабирования, нужно заложить функционал что бы поля сводной (главной) таблицы брались из записей другой (таблица критериев, с полями: id_критерия, наименование_критерия). Но собственно подобная реализация мне не встречалась. Буду признателен, если направите в нужное русло.
Введите:
1. Отдельные понятия определений из групп (по-отдельности): "Симптом", "Диагноз".
2. Определите зависимости понятий между собой в этих группах - сформируйте "деревья"-симптомов (для разных болезней) и "деревья"-диагнозов (тоже для разных болезней).
3. Определите взаимосвязь между деревьями-симптомами и деревьями-диагнозами.
4. Определите списки "Лечения" для каждого дерева-диагноза - это порядок действий/процедур при лечении конкретного диагноза.
5. А вот уже в этих списках - укажите нужные коэффициенты по каждому действию/процедуре.
Если честно, не совсем понял. Карта контроля качества содержит в себе и так диагноз - симптомов нет. Для всех диагнозов перечень критериев контроля качества одинаков. Просто они сами по себе могут взять и изменится.
Я рассматривал вариант, создания простой таблицы, где каждый из критериев это отдельное поле. Но как то топорно.
Карта контроля качества содержит в себе и так диагноз - симптомов нет. Для всех диагнозов перечень критериев контроля качества одинаков. Просто они сами по себе могут взять и изменится.
Диагноз без симптомов - это интересное лечение будет.... :(
Если перечень критериев для всех диагнозов будет одинаков - создавайте НАБОРЫ (из общего списка) критериев (по битовой маске, например). Тогда при изменении коэффициентов в общем списке - наборы будут автоматом пересчитываться.
xmoonlight, Лечение произошло. Симптоматика уже не важна. Важен факт - как пациент пролечен. И собственно это "как" формируется из набора коэффициентов (среднее по всем).
Можно подробнее про наборы. Как это создать в схеме БД?
Лечение произошло. Симптоматика уже не важна. Важен факт - как пациент пролечен.
Лечение начинают после определения состояния болезни пациента по симптоматике и анализам/исследованиям.
Интервал между определением состояния и окончанием лечения - это и есть лечение. А цель (после определения состояния пациента) и последовательность действий для достижения этой цели - это планируемый процесс лечения (или ТЗ).
Вот на основе начального состояния пациента (после всех обследований), выбранных действий для лечения (перечень работ) и конечным результатом (когда мы понимаем, что вылечили) и нужно получить список проделанных действий и процент достижения конечной цели: ВЫЗДОРОВЛЕНИЯ.
Пролечить можно: правильно/ошибочно и с определённым процентом достижения целевого результата.
xmoonlight, Вы не совсем понимаете контроль качества. То каким образом лечили пациента роли не играет. Есть определённый ряд критериев, которым должен соответствовать случай заболевания. Ряд критериев для всех случаев одинаковый абсолютно, нет разницы какое было заболевание, когда оно началось или когда оно закончилось. И даже, по сути, нет разницы умер пациент, или нет (в рамках данной таблицы). Его смерть, это просто будет минут бал, жирный конечно, но по сути просто бал.
Так вот, есть ряд критериев, есть пациент, есть врач, есть сама карта контроля. Вот "таблицы". Надо каким нибудь образом смоделировать БД, что бы в случае изменения набора критериев (может МинЗдрав решит избавится от какого-либо критерия) я не менял структуру таблицы "карта контроля".
Sadus, ну и что тут сложного? просто "плоский" список критериев.
Только вот по баллам - странно.
Должно быть 1.0/11=0.0909... - на каждом критерии. А общий балл: 1.0 (т.е. 100%)
И уже в этих рамках - можно менять веса при необходимости у пунктов критериев или добавлять новые, распределяя эти 100% по всем равномерно или не равномерно.
Как я понял коэффициенты критериев привязаны к экспертам 1-го и 2-го уровня. И у каждого уровня - они разные. (Или даже у конкретного человека?!)
Нужно составить взаимосвязи между 3-мя параметрами:
1. перечень критериев
2. уровень эксперта (или конкретный человек-эксперт)
3. коэффициенты по списку критериев (п.1) по каждому уровню(человеку) (п.2)
Т.е. создание связи у нас в обратном порядке: п.2 или 3., затем оставшийся (п.2 или п.3), и только в конце - п.1: здесь мы связываем все записи в одну законченную логическую цепочку.
xmoonlight, Как считаете, можно ли еще нормализовать что то? БД будет наполнятся из C# приложения, вроде как запрограммировать адекватное наполнение можно.
Sadus, 1. (меня все за это ненавидят) Забудьте про поле "pass" как про страшный сон в базе данных. Есть только поле hpass/hashpass - хешированный пароль и salt - соль для конкретного пользователя.
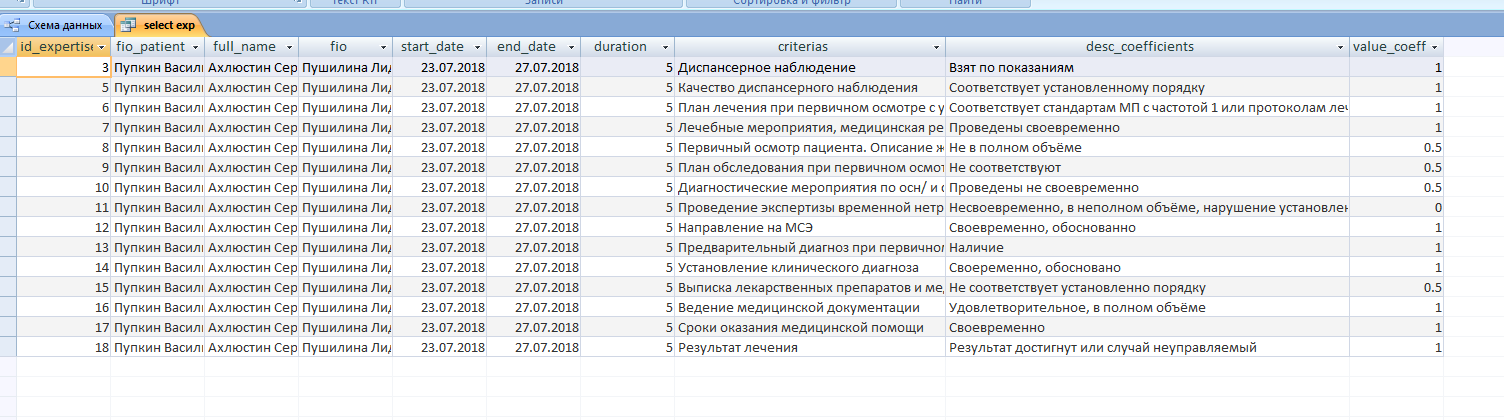
2. start_date, end_date, duration - зачем тут duration?! Это лишнее поле статических данных, которое впоследствии может привести к ошибкам. Нужно вычислять всегда: duration = end_date - start_date
3. id_expert_1_lvl - если начали считать левелы (т.е. появились типы экспертов), то сразу нужно делать отдельную таблицу левелов.
4. fio* и full_name - лучше разделить на 3-и отдельных поля.
5. роли всех пользователей нужно сделать в одной таблице и добавить таблицу типов: "admin", "helpdesk", "доктор", "пациент", "заведующий" и т.д. и уже оттуда по ID-шникам ролей - распределять по бизнес-процессу.
Подумал еще над логикой, и понял, что нужно сделать отдельную таблицу для экспертизы 1 уровня и экспертизы 2 уровня. Ведь эксперты в этом случае разные. И связывать два уровня в одной сводной таблице.
Единственное что смущает, это связь между уровнем экспертизы - критерием - значением критерия. какая то дублирующая связь получается.
Sadus, (criterias и coefficients в таблицах expertise_1lvl и expertise_2lvl нужно заменить на criterias_id и coefficients_id)
см. п.3 в моём предыдущем комментарии.
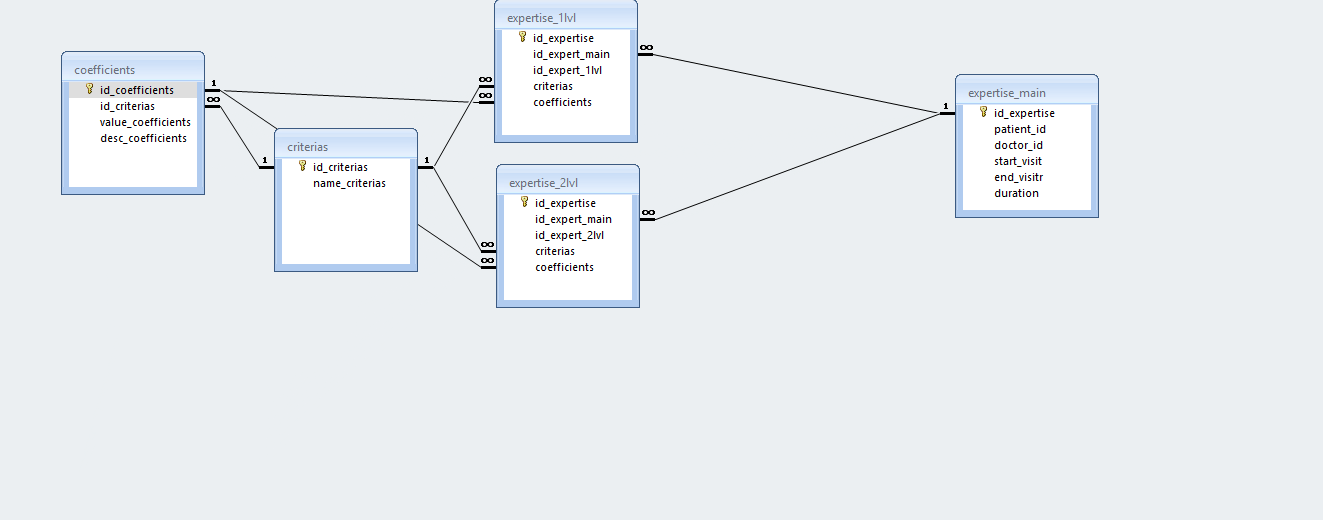
Добавлю, что для корректной работы базы по экспертам, цепочки связей должны быть такими (указаны таблицы и типы связей: 8 - знак бесконечности):
1. [users] 1<-8 [expertise_main]
2. [criterias] 1<-8 [coefficients] 8->1 [expertise_main]
3. [expert_level] 1<-8 [coefficients]
1. В любой экспертизе есть определённые конкретные люди.
2. Коэффициент (дробный показатель) состоит из критерия (название) и привязан к конкретной экспертизе.
3. Каждый коэффициент однозначно определяется уровнем эксперта.
1) про соль понял. уже реализовал хранение пароля в закрытом виде, до соли пока еще не добрался(
2) duration - нужна будет сортировка, статистика по продолжительности случаев заболевания, я не думаю, что хорошей идеей потом будет вычислять всё в СУБД - мне казалось лучше сохранить это поле сразу и не парится. Или я не прав?
3)Чуть ниже уже есть разделение на 2 уровня экспертиз
4) А чем обосновано деление full_name на first_name, last_name и т.д? Есть какие то положительные стороны такого подхода в производительности или удобстве?
5) У меня из ролей только оператор (он же эксперт 1 уровня) и главный врач (только он эксперт 2 уровня). Поэтому делить то особо нечего, я буду разграничивать роли по статусу "таблица status"
xmoonlight, набор критериев, или иной подход к подсчёту результатов не требуется когда проводится ре экспертиза - по сути, это та же самая экспертиза (1lvl) только проводится более высокой должностью.
Если 1 сделал, то 2 застопорило. Зачем нам связывать таблицу коэф. с главной таблицей? Ведь данные о критериях и коэф. хранятся в таблицах expertise_X_lvl
Sadus, если будет у Вас потом 3-ий или 4-ый левел? почему не проще сделать таблицу левелов экспертизы (как я уже выше написал)?
Всегда, если появляется 2 или более однотипных свойства (как здесь в случае с левелами экспертизы) нужно заводить хранилище под него: отдельную таблицу с ID-шниками и необходимым набором записей (для текущей ситуации: 2 записи).
1) про соль понял. уже реализовал хранение пароля в закрытом виде, до соли пока еще не добрался(
ок.
2) duration - нужна будет сортировка, статистика по продолжительности случаев заболевания, я не думаю, что хорошей идеей потом будет вычислять всё в СУБД - мне казалось лучше сохранить это поле сразу и не парится. Или я не прав?
я написал аргумент выше.
Ок. Есть ещё вариант хороший: хотите ещё столбец duration - сделайте триггер на изменение записи для поля duration. Чтобы значение там всегда считала база данных.
3)Чуть ниже уже есть разделение на 2 уровня экспертиз
Всегда, если появляется 2 или более однотипных свойства (как здесь в случае с левелами экспертизы) нужно заводить хранилище под него: отдельную таблицу с ID-шниками и необходимым набором записей (для текущей ситуации: 2 записи).
4) А чем обосновано деление full_name на first_name, last_name и т.д? Есть какие то положительные стороны такого подхода в производительности или удобстве?
Скорость поиска базы и удобство редактирования в GUI на фронте.
5) У меня из ролей только оператор (он же эксперт 1 уровня) и главный врач (только он эксперт 2 уровня). Поэтому делить то особо нечего, я буду разграничивать роли по статусу "таблица status"
Тут Вам виднее: не готов даже спорить (т.к. пока плохо понимаю взаимосвязи ролей).
Sadus, "Связывает набор критериев и вариации их значений" - бессмысленная связь. Т.к. Вы всё храните в expertise_1lvl и по ней можно сделать выборку используемых (не "мёртвых") значений по каждому критерию. Я бы убрал эту связь, а остальное - вроде норм.


 Средний
Средний
 Средний
Средний
 Простой
Простой
 Средний
Средний