Здравствуйте!
На руках имеется 10 тысяч пар матриц (входная и выходная) 100*100, причем входную можно преобразовать во выходную, применив некий закон, который мне неизвестен.
Входные матрицы содержат дробные значения широкого диапазона: от нуля до нескольких тысяч (95% - нули), а выходные - целочисленные значения (95% - нули), отражающие принадлежность к одному из 16 классов.
Помимо этого, есть 1 тысяча входных матриц 100*100, для которых нужно более-менее точно воспроизвести выходные.
Первая мысль, которая мне пришла в голову, это то, что передо мной задача регрессии, а значит нейросети должны помочь. Т.к. входная и выходная матрицы имеют равную размерность, то осмысленно использовать архитектуру вида U-Net/DeconvNet/SegNet/RedNet/FCN. Выбор пал на RedNet:
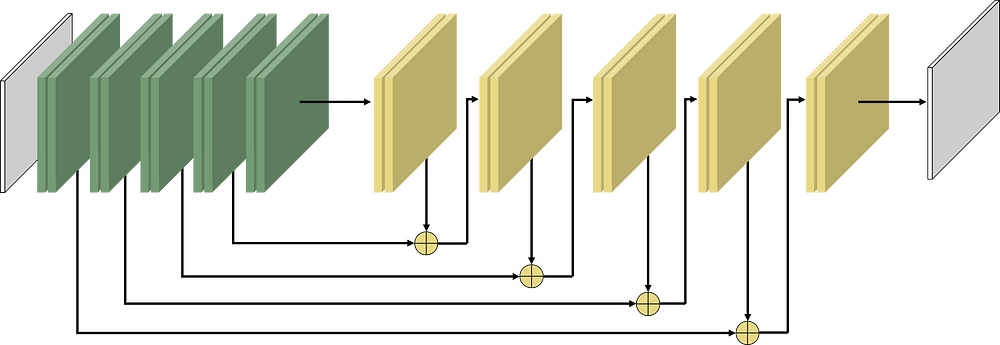
Если использую активационную функцию последнего слоя Sigmoid, то, после обучения на 2.5к образцов, получаю точность около 0.5 и полную кашу в выходных данных. Если активационная функция ReLu, то точность получается 0.9, но в выходных данных правильно определяются только нули, а остальные значения уходят за пределы тысячи.
Ранее доводилось обучать только U-Net в задаче сегментации на "дорога есть" и "дороги нет".
Не ошибся ли я с выбором архитектуры?
Если нет, то, полагаю, ошибся я в том, как обучаю нейросеть: нужно разбить выходную матрицу на 16 матриц-масок, где содержалась бы информация о наличии только конкретного класса в данной ячейке матрицы. Т.е. как это делается в U-Net, когда осуществляется сегментация на несколько классов. Ну и активационная функция последнего слоя будет SoftMax, а выходных масок будет 16. Верна ли моя догадка?


 Простой
Простой







