Сразу скажу, я в нюансах не силен, знаю sql в общих чертах.
Сейчас пагинация сделана стандартно через запоминание последнего айди. Примерно так:
SELECT *
FROM recording WHERE recording.id > 0 AND recording.artist_id = '269608'
ORDER BY recording.id
LIMIT 10
Запрос идет 5-10 секунд. План запроса здесь
https://explain.depesz.com/s/a8Xl
Как видно больше всего времени тянет сканирование индекса, не пойму почему.
Если убрать ORDER BY , то все веселее
https://explain.depesz.com/s/WpTp
Еще заметил, что если айдишник артиста не 269608, а меньше, например 500, то запрос идет очень быстро. И чем больше айдишник, тем дольше выполняется запрос. Разве это нормально? Такое впечатление, что все айди пересчитываются по порядку пока не дойдет до нужного.
В общем, как быть без ORDER BY, если нужна и скорость (в первую очередь) ну и фильтрация данных?
Таблица содержит 18млн записей, но не думаю, что это прямо таки неподъемная схема для субд (?)
UPD
Опишу задачу полностью.
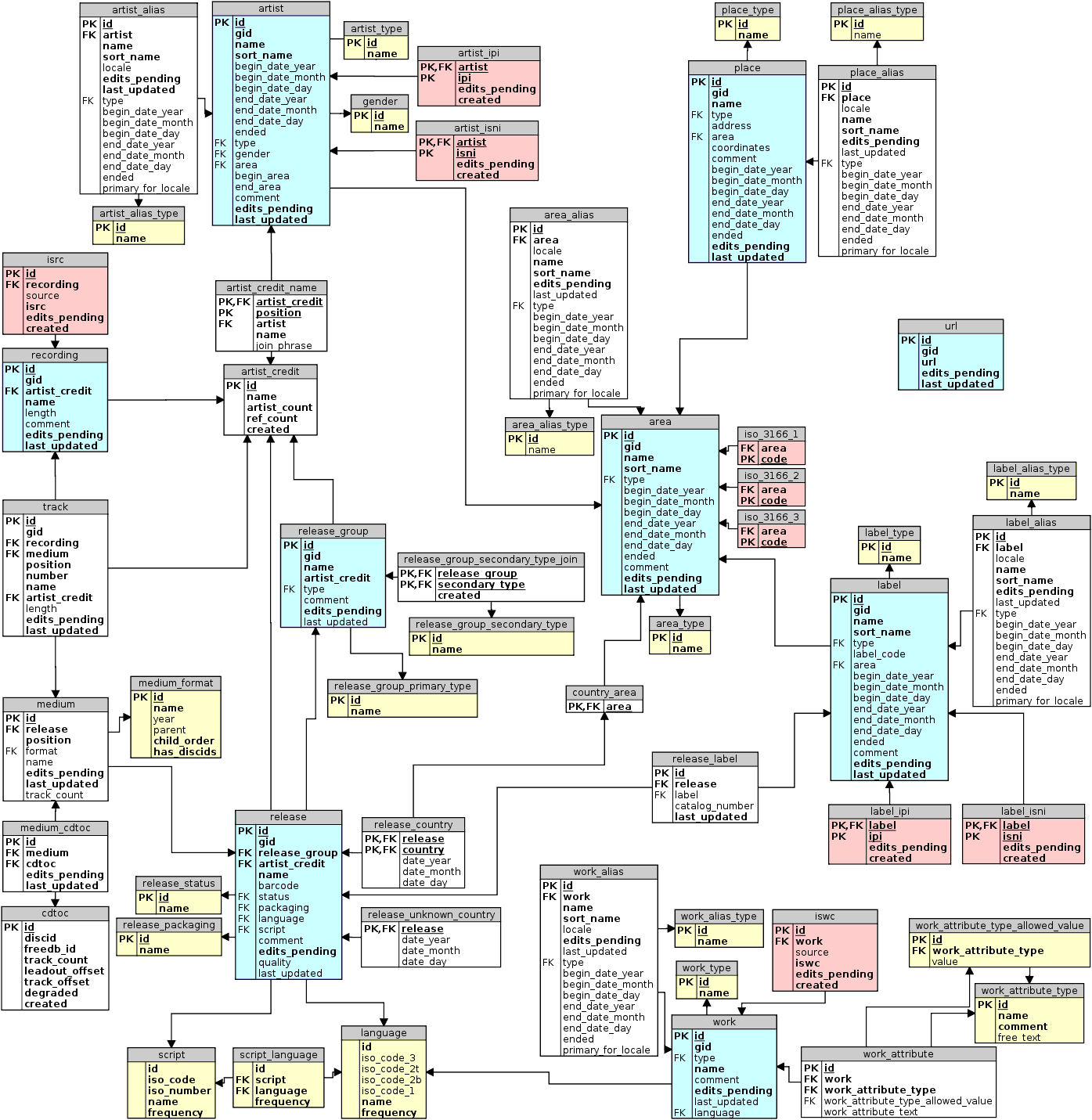
Нужно достать треки по айдишнику артиста. Треки лежат в таблице recording, артисты - в таблице artist. Но таблицы не связаны напрямую, а только посредством двух других - artist_credit_name и artist_credit.
Связь следующая: artist.id <--> artist_credit_name .artist, artist_credit_name .artist_credit <--> artist_credit.id <--> recording.artist_credit
Вся схема
здесь
Полностью запрос выглядит так:
SELECT recording.id AS "recordingId", recording.name AS "trackName", artist.name AS "artistName"
FROM artist
INNER JOIN artist_credit_name ON artist.id = artist_credit_name.artist
INNER JOIN artist_credit ON artist_credit_name.artist_credit = artist_credit.id
INNER JOIN recording ON artist_credit.id = recording.artist_credit
WHERE artist.id = $(artistId) AND recording.id > $(index)
ORDER BY recording.id LIMIT $(limit)
Получается так, что одному `artist.id` может соответствовать несколько `artist_credit.id`. Поэтому я пытался переписать запрос таким образом, что сначала выбираем все `artist_credit.id` для данного артиста а потом по ним уже с помощью `WHERE IN` выбирать треки, ускорение примерно на 30% (хотя может это погрешность), но результат все равно не тот что нужен.
Индексы по таблицам :
recording: id (PK),
artist_credit: id (PK),
artist_credit_name: id (PK), artist(FK),
artist: id (PK)
Может добавить индекс на поле `recording.artist_credit` ? Не знаю можно ли добавлять индексы на внешние ключи?
UPD#2 Добавил индекс на `recording.artist_credit`, теперь запрос идет быстро


 Средний
Средний
 Простой
Простой
 Простой
Простой

{kind=link}