Доброго времени суток.
Представим, что в простейшем случае у нас есть 2 сервиса. Первый предоставляет доступ к клиентской базе, второй содержит финансовые данные (заказы, покупки, счета, переводы средств со счета на счет, все что угодно). По воле случая эти сервисы находятся на разных машинах, и имеют разные базы данных. Потребители этих сервисов отлично работают: клиентская база растет, количество заказов увеличивается. Пользователям предоставляется статистика их операций, все гладко. А теперь нам нужно построить некоторую отчетность, которая агрегирует данные финансового сервиса с привязкой к клиенту. Например, заделались мы налоговым агентом (
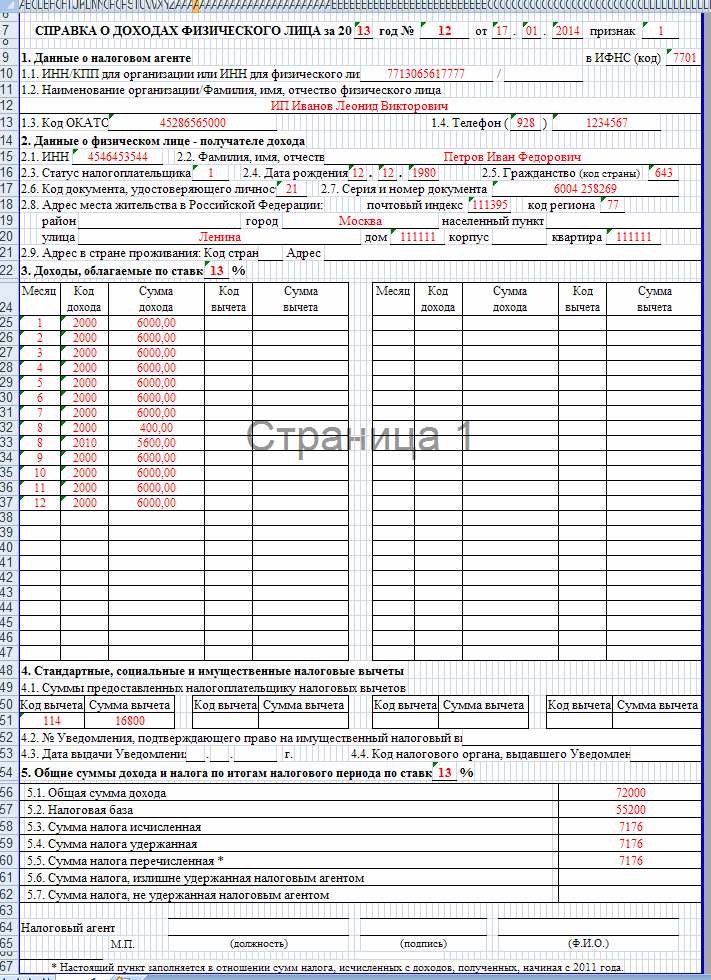
Wiki), и хотим нагенерить для всех наших клиентов справок 2НДФЛ с разбивкой доходов по месяцам (
пример справки). Если бы это была одна база данных, это был бы один кросс-запрос по таблицам касающихся как персональных, так и финансовых данных (можно даже сразу выбрать XML, который тут же отдать на откуп View, построящему отчеты). Это гарантировано работает быстро. А как правильно поступить в случае разнесенных данных? Выбрать сначала список всех клиентов с одной стороны, затем данные по доходам с другой, и клеить их в коде? Не в разы ли уменьшается скорость формирования?




{kind=link}