Здравствуйте.
Есть парсер, который кушает html с чужого сервера (в пределах РФ) и возвращает некоторые данные в формате json. Пока нагрузка была 40к запросов в сутки, все было здорово. Но в данный момент количество запросов значительно увеличилось. И с этого момента, время на выполнение скрипта стало доходить до 10-20 секунд!
Операции:- require библиотеки QueryPHP
- запрос на другой сервер с получением 100кб кода html
- инициализация класса QueryPHP
- извлечение содержимого 8 элементов DOM из ответа
- запрос в локальную базу данных PHP::PDO методом SELECT
- вывод объекта json.
Пожалуйста помогите понять, что нужно сделать? Есть ли смысл менять тариф у хостера? Хостер говорит, что производительность в первую очередь зависит от скрипта, а не от железа, и более дорогой тариф вряд ли решит мою проблему.
Конфигурация: VPS OpenVZ / Xeon 400MHz / 512mb / RAID HDD
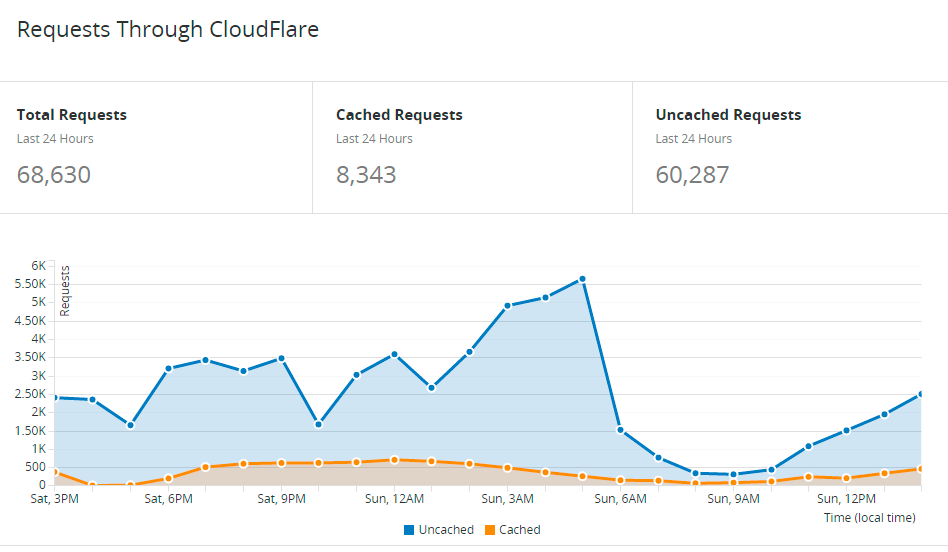
Статистика CloudFlare (сейчас прокси отключен)
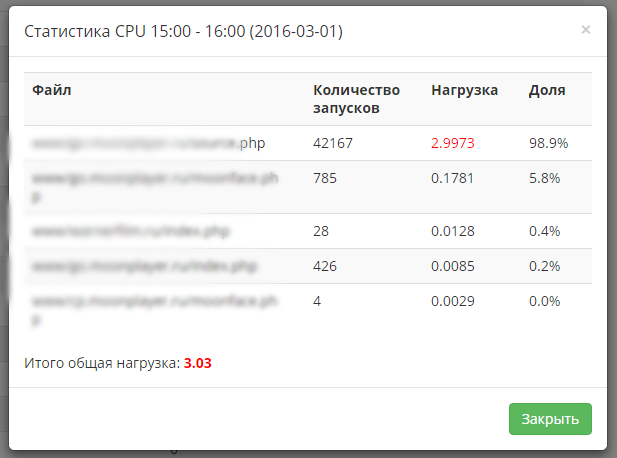
Статистика от хостера за 1 час.