Добрый день!
Подскажите куда "копать", суть проблемы вот в чем:
С помощью xlrd и xlwt пытаюсь обработать небольшой прайс лист 1500 строк! - но в конечном фале появляется только первые 130 - 200 строк, но чаще вообще ничего.
А при открытии конечного фала new_price.xls EXCEL-ем выдает сообщение "
В книге "new_price.xls" обнаружено содержимое, которое не удалось почитать. Попробовать восстановить содержимое книги? Если доверяете источнику этой книги, нажмите кнопку Да"
Если же открыть через OpenOffice Calc = то после выше указанных 130-250 (каждый раз по разному) в строке с названием идет "наборы всяких значков и символов" и далее в артикуле!
Если отключить вывод в прайс названия (ws.write(num,1,v[0])) то все нормально - и артикул и цены на месте, и EXCEL не ругается при открытии.
Если обрабатывать строк 150 - 200 то проблем тоже нет с русскими буквами!
Если заменить все названия в исходном файле текстом чисто на русского языке - то проблем тоже не возникает! т.к. в оригинале в названиях и русские и английские слова (+ цифры, скобки, кавычки, и т.д. н они не влияют на проблему)
Вот упрощенный код:
#-*- coding: utf8 -*-
import xlrd, xlwt
import os
from trans import transliterate # самописная функция транслитерации
# благодаря ей понял что дело
# не в спец. символах, а Русских символах!
file = '01.xls' # исходный файл EXCEL
art = 0 # столбец с Артикулом
names = 1 # столбец с Названием товара
price = 2 # столбец с Цена товара
data = {} # Словарь в него записываются данные для обработки
# в формате {'Артикул':('Название', 'Цена')}
n = 0
directory = os.getcwd() # Определяем текущий путь
mybook = xlrd.open_workbook (directory + '\\' + file, on_demand=True) #encoding_override='utf8' # пробовал разные кодировки не помогает
list = mybook.sheet_names()[0]
sheet = mybook.sheet_by_name(list)
for s in range(sheet.nrows):
if sheet.row_values(s)[names] == '': # Проверяем что в names и приводим к строке
name = 'нет имени'
else:
if type(sheet.row_values(s)[names]) is str:
name = sheet.row_values(s)[names]
else:
name = str(int(sheet.row_values(s)[names]))
name = transliterate(name) # обработал name через транслитерацию и понял что дело в русских буквах!!!
# для нижнего скрина в транслитерации "выключил" замену буквы б,
# при полной замене всех русских символов английскими конечный прайс открывается нормально!
data[str(int(sheet.row_values(s)[art]))] = (name, sheet.row_values(s)[price]) # Заполняем словарь с вложенным кортежем
n = +=1
mybook.release_resources() # после обработки выгружаем ресурсы -> '01.xls'
wb = xlwt.Workbook() #encoding='utf8' # пробовал разные кодировки не помогает
ws = wb.add_sheet('Test') #,cell_overwrite_ok=True)
num = 1
for k,v in data.items():
nums = num
k = k.replace(' ','')
ws.write(num,0,k)
ws.write(num,1,v[0]) # <- вот ТУТ чтото не так
print (v[0]) # хотя печатает все 1500 позиций в консоли на родном русском, когда отключена транслитерация!
ws.write(num,2,v[1])
num += 1
ws.write(1501,1,'ПРИВЕТ') # при наличии русских букв в словаре этой надписи в конечном файле (new_price.xls) нет!
wb.save('new_price.xls') # сохраняем конечный результат
print ('ГОТОВО!')
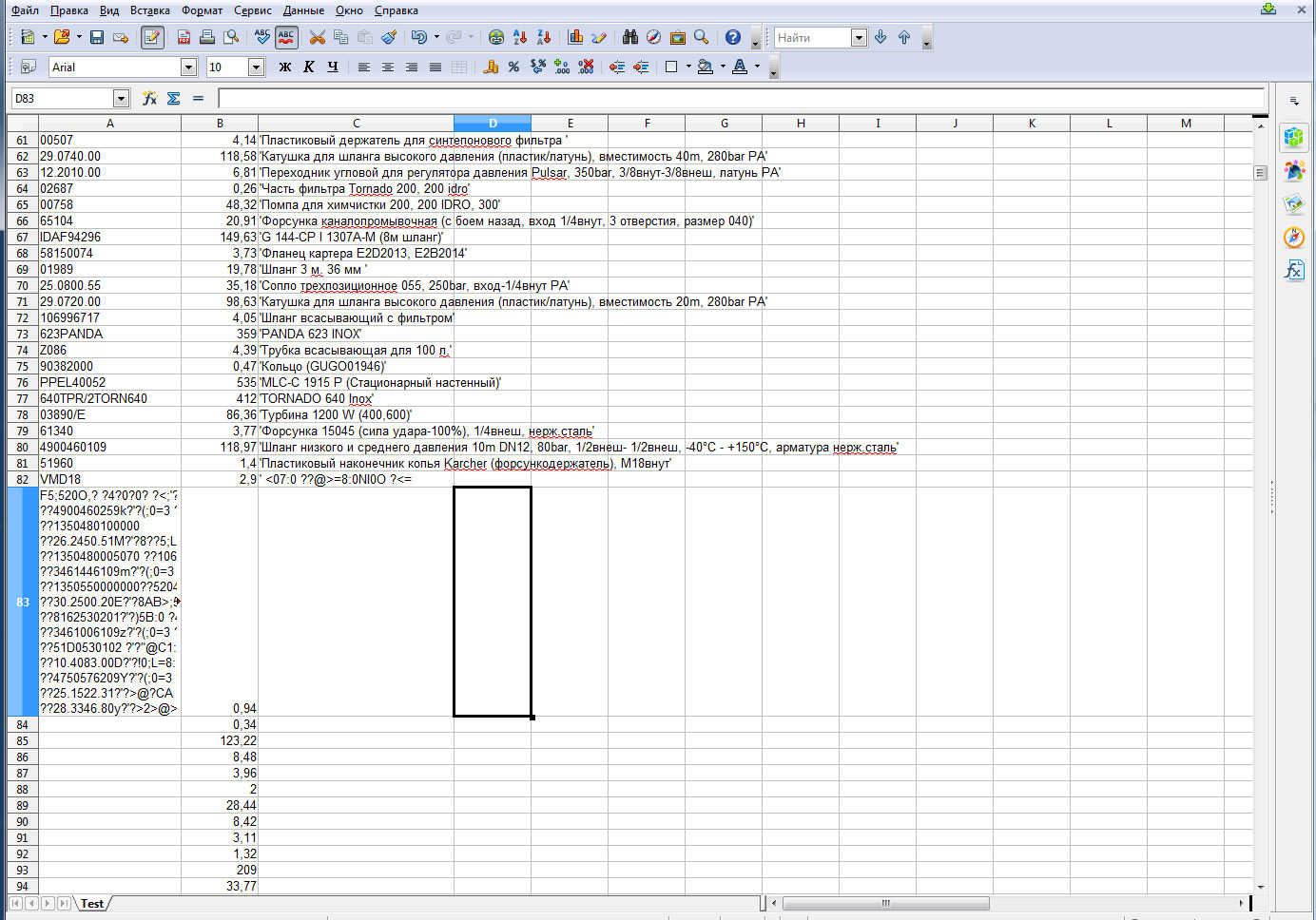
Вот скрин что тварится в OpenOffice Calc при открытии - из-за наличия одной только буквы русской 'б' в конечном прайсе, в столбец с Артикулами (первый) влитают все последующие названия, цены самое интересное остаются как надо (видно по тому что они в float)
Обратите внимание на 214 строку в ней в названии tur
бonasadka отображает корректно букву б
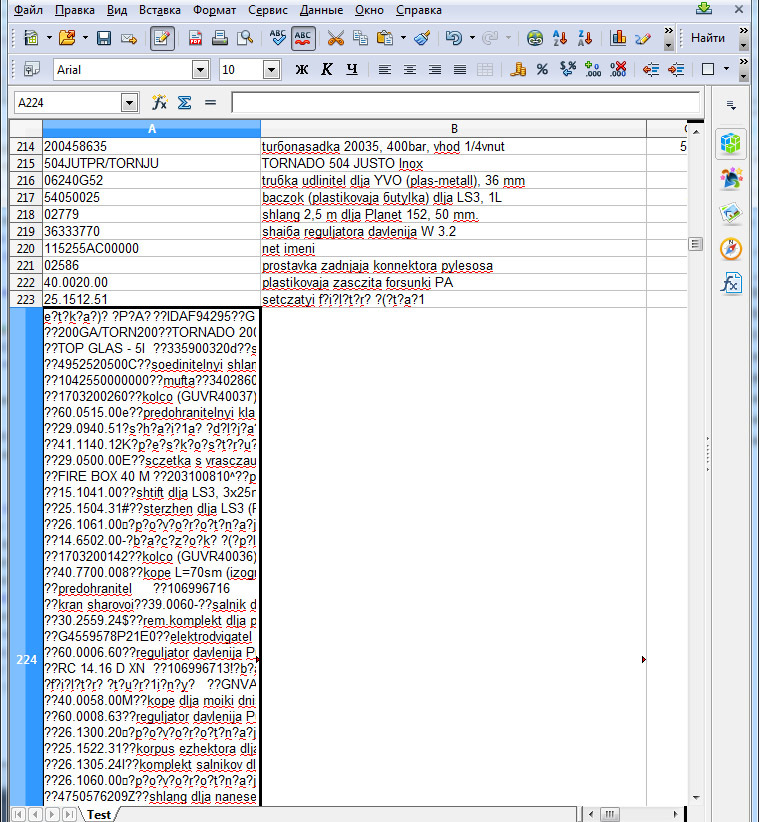
Вот еще скрин (без использования транслитерации):
впечатление такое что "словарь" data сходит с ума....