Доброго времени суток, хабраюзеры!
Столкнулся с непонятным для меня явлением в моей любимой СУБД — PostgreSQL.
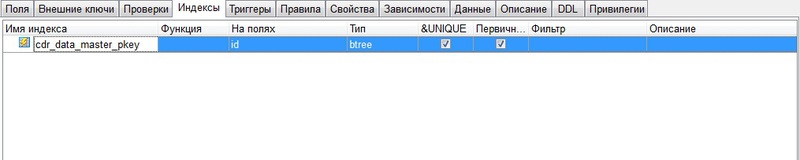
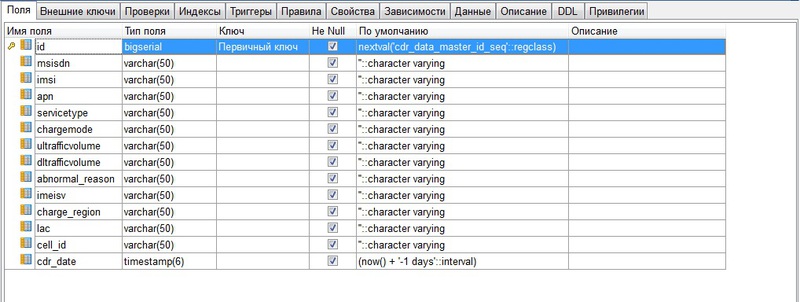
Суть такова. Имеются две таблицы с одинаковыми данными. Первая — обычная, вторая — партицированная по автоинкрементному индексу (каждая партиция содержит 5 млн записей). Этот же индекс является primary key в обоих таблицах. Проблема в том, что запросы, связанные с сортировкой по этому primary key, в партицированной таблице выполняются неприлично долго. Например (индекс традиционно назван id):
1) на обычной таблице:
explain analyze (select * from my_data order by id desc limit 10);
QUERY PLAN
------------------------------------------------------------------------------------------------------
Limit (cost=0.00..7.26 rows=10 width=418) (actual time=0.012..26.831 rows=10 loops=1)
-> Index Scan Backward using my_data_pkey on my_data (cost=0.00..20081200.21 rows=27676900 width=418) (actual time=0.010..26.809 rows=10 loops=1)
Total runtime: 26.864 ms
(3 rows)
* This source code was highlighted with Source Code Highlighter.
2) на партицированной таблице:
explain analyze (select * from my_data_master order by id desc limit 10);
QUERY PLAN
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------
Limit (cost=2189687.00..2189687.02 rows=10 width=100) (actual time=314882.294..314882.314 rows=10 loops=1)
-> Sort (cost=2189687.00..2305298.08 rows=46244433 width=100) (actual time=314882.292..314882.301 rows=10 loops=1)
Sort Key: public.my_data_master.id
Sort Method: top-N heapsort Memory: 26kB
-> Result (cost=0.00..1190361.43 rows=46244433 width=100) (actual time=209.347..250605.224 rows=46495464 loops=1)
-> Append (cost=0.00..1190361.43 rows=46244433 width=100) (actual time=209.343..168812.754 rows=46495464 loops=1)
-> Seq Scan on my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_5mln my_data_master (cost=0.00..0.00 rows=1 width=98) (actual time=0.002..0.002 rows=0 loops=1)
-> Seq Scan on my_data_10mln my_data_master (cost=0.00..0.00 rows=1 width=99) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_15mln my_data_master (cost=0.00..0.00 rows=1 width=99) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_20mln my_data_master (cost=0.00..0.00 rows=1 width=98) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_25mln my_data_master (cost=0.00..0.00 rows=1 width=99) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_30mln my_data_master (cost=0.00..81068.66 rows=1934658 width=100) (actual time=209.329..7484.434 rows=1934658 loops=1)
-> Seq Scan on my_data_35mln my_data_master (cost=0.00..85868.90 rows=126902 width=100) (actual time=9.837..7667.541 rows=247612 loops=1)
-> Seq Scan on my_data_40mln my_data_master (cost=0.00..85877.48 rows=54482 width=100) (actual time=11.843..8542.494 rows=107813 loops=1)
-> Seq Scan on my_data_45mln my_data_master (cost=0.00..85970.71 rows=82715 width=101) (actual time=16.713..8438.728 rows=162790 loops=1)
-> Seq Scan on my_data_50mln my_data_master (cost=0.00..114586.52 rows=3532521 width=100) (actual time=12.295..9758.697 rows=3532521 loops=1)
-> Seq Scan on my_data_55mln my_data_master (cost=0.00..90983.00 rows=5000000 width=100) (actual time=19.895..6268.184 rows=5000000 loops=1)
-> Seq Scan on my_data_60mln my_data_master (cost=0.00..90966.00 rows=5000000 width=100) (actual time=14.538..6459.220 rows=5000000 loops=1)
-> Seq Scan on my_data_65mln my_data_master (cost=0.00..90746.00 rows=5000000 width=100) (actual time=9.685..6464.820 rows=5000000 loops=1)
-> Seq Scan on my_data_70mln my_data_master (cost=0.00..90985.00 rows=5000000 width=100) (actual time=11.304..6468.359 rows=5000000 loops=1)
-> Seq Scan on my_data_75mln my_data_master (cost=0.00..90958.00 rows=5000000 width=100) (actual time=17.406..6389.408 rows=5000000 loops=1)
-> Seq Scan on my_data_80mln my_data_master (cost=0.00..90970.00 rows=5000000 width=99) (actual time=13.072..6537.780 rows=5000000 loops=1)
-> Seq Scan on my_data_85mln my_data_master (cost=0.00..90950.00 rows=5000000 width=99) (actual time=8.716..6582.697 rows=5000000 loops=1)
-> Seq Scan on my_data_90mln my_data_master (cost=0.00..90934.00 rows=5000000 width=99) (actual time=11.954..6799.891 rows=5000000 loops=1)
-> Seq Scan on my_data_95mln my_data_master (cost=0.00..9274.07 rows=510070 width=100) (actual time=7.106..640.611 rows=510070 loops=1)
-> Seq Scan on my_data_100mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.003..0.003 rows=0 loops=1)
-> Seq Scan on my_data_105mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_110mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_115mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_120mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.000..0.000 rows=0 loops=1)
-> Seq Scan on my_data_125mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_130mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_135mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_140mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_145mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_150mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_155mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_160mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_165mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_170mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_175mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_180mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_185mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_190mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_195mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
-> Seq Scan on my_data_200mln my_data_master (cost=0.00..10.14 rows=140 width=532) (actual time=0.001..0.001 rows=0 loops=1)
Total runtime: 314882.697 ms
(48 rows)
* This source code was highlighted with Source Code Highlighter.
Такая же история с запросом типа:
select max(id) from my_data_master;
* This source code was highlighted with Source Code Highlighter.
Подскажите, гуру, есть какая-либо хитрость в индексах для партицированных таблиц?

 Простой
Простой
 Средний
Средний