Допустим у нас есть тяжёлая(десятки миллионов) таблица куда записываються заявки:
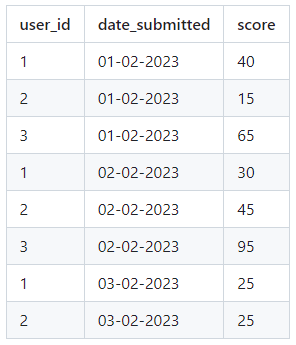
Даны две даты
start_date и
end_date. В этом диапазоне нужно найти пользователей с наивысшим баллом (score) по дням. Также пользователь должен присутствовать в выборке лишь в том случае, если он подавал заявку каждый день в течении запрошенного периода. Как оптимальнее всего организовать хранения таких данных и чтобы потом максимально быстро доставать оттуда данные для отчётов?
Пример запроса:
start_date: 01-02-2023, end_date: 03-02-2023
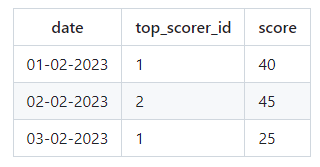
1 февраля пользователь с ID 3 имел наивысший балл, но причина по которой он не появился в отчете, заключается в том, что в данный период (с 1 по 3 февраля включительно) он не каждый день подавал заявку (пропустил 3 февраля). Есть только два пользователя (пользователи 1 и 2), которые подавали заявки каждый день в течение данного периода. Таким образом, 1 февраля User ID 1 стал лучшим пользователем, обогнав User ID 2 на 40 баллов, набравшего 15 баллов. 2 февраля по аналогичной логике победителем стал пользователь с ID 2 (он обошёл пользователя с ID 1). 3 февраля, используя аналогичную логику, пользователи с идентификаторами 1 и 2 набрали равное количество баллов, и мы случайным образом выбрали пользователя с идентификатором 1 среди лучших за день.




 Простой
Простой

