У меня есть схема вышивки в pdf файле, я могу выделять каждый символ, производить поиск по нему в этом файле.
Пример:
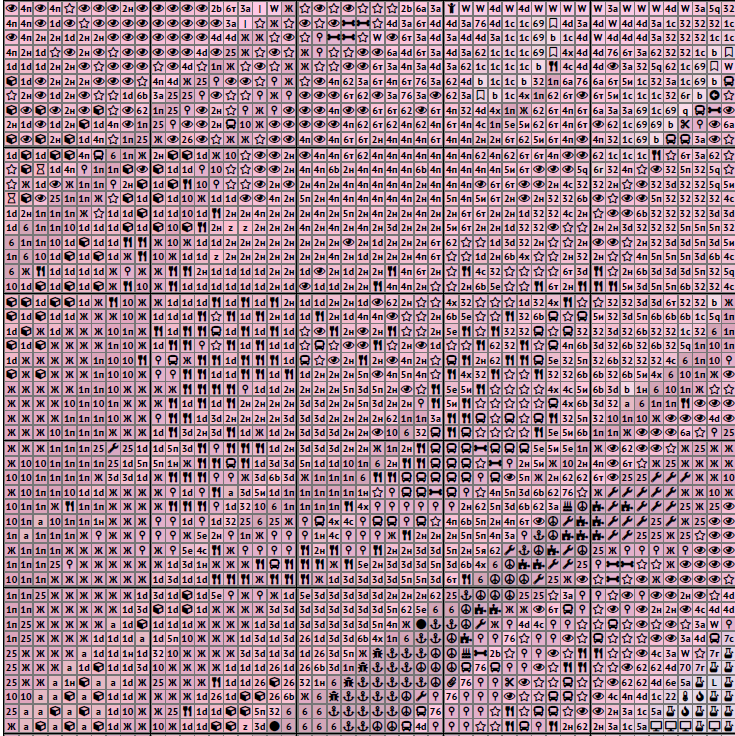
Я хочу через python посчитать количество каждого символа на странице и вывести в отдельный текстовый файл. Сначала я подумал что это простая задача - загрузил pdf через PyPDF2, извлек текст и посчитал через Counter.
import PyPDF2
from collections import Counter
pdf_file = open('example.pdf', 'rb')
pdf_reader = PyPDF2.PdfReader(pdf_file)
symbol_counter = Counter()
page = pdf_reader.pages[0]
text = page.extract_text()
symbol_counter.update(text)
pdf_file.close()
for symbol, count in symbol_counter.most_common():
print(f'{symbol} - {count}')
Но когда я начал выводить результаты, то столкнулся с проблемой кодировки (как я понял), из-за которой вывод у меня выглядел примерно так:
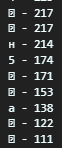
Как мне решить эту задачу? Что я упускаю?
Вот пример pdf файла 

