Сейчас я продумываю план/архитектуру (idk как правильно назвать) тг бота и не могу разобраться
Главная фишка моего бота – full-text поиск.
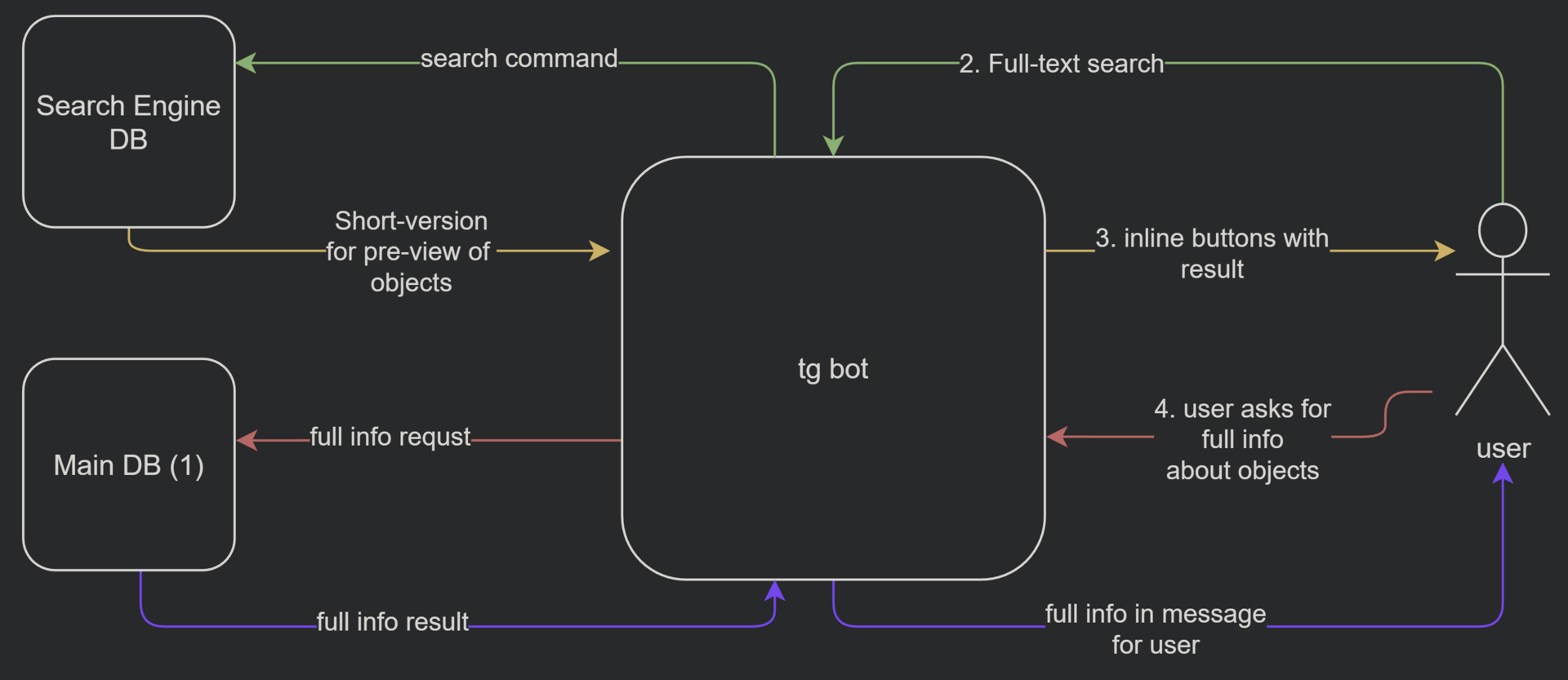
1. Мне нужно место, где я буду хранить данные 10 000 элементов, у каждого элемента будут:
- Тэги (~200 символов)
- Описание (1000 символов)
- Фото (1 МБ)
- Геолокация
2. К этому хранилищу мне нужен full-text поиск по таким параметрам как:
-Геолокация
-Тэги
-Описание
3. Затем результаты поиска будут форматироваться в инлайн кнопки (и в запросах, которые выводятся юзеру будут сокращенные версии информации об объектах, чтобы это помещалось в инлайн кнопки) и отправляться юзеру
4. И затем пользователь уже запрашивает полную версию информации об обьекте (т.к. нажимая на инлайн кнопки, он выбирает id из БД с полной информацией), и соотвественно её получает
> Инфраструктура должна поддерживать 1000 одновременных полнотекстовых запросов по показателям указанным выше
Моя проблема:
**Как стоит продумать архитектуру проекта? Какие инструменты лучше использовать? Использовать один сервер или несколько?**
Мои варианты:
Инструмент для full-text поиска, который мне понравился больше всего – ElasticSearch, но я полагаю, что лучше не надо использовать его как основную базу данных.
Значит в качестве основной базы данных нужна какая-то другая БД. Мой главный критерий – возможность иметь базовую статистику по данным (насколько нагружена БД, когда и сколько объектов появилось в системе) а также максимальную быстродейственность, т. к. ресурсы ограничены и хотелось бы иметь лучшее решение. И тут я не могу выбрать: PostgresQL или MongoDB. Не будет ли SQL база слишком требовательна к ресурсам? Может стоит выбрать sphinx а не elasticsearch? Или я мыслю совершенно в неправильном русле?


 Средний
Средний
 Средний
Средний
