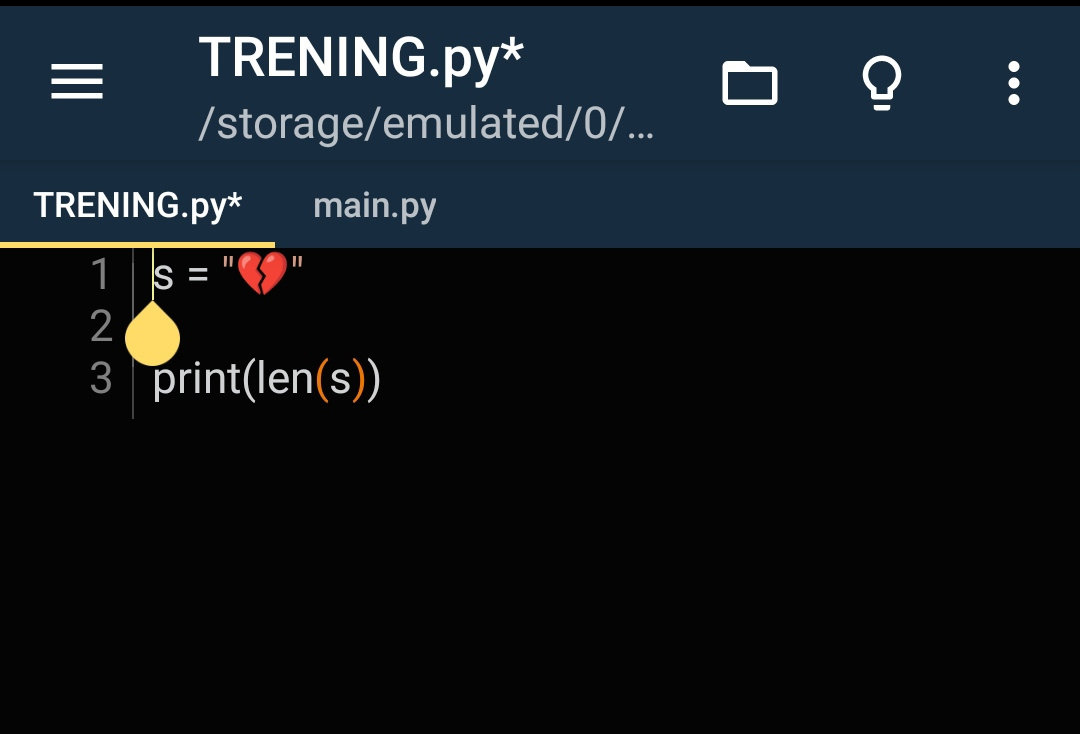
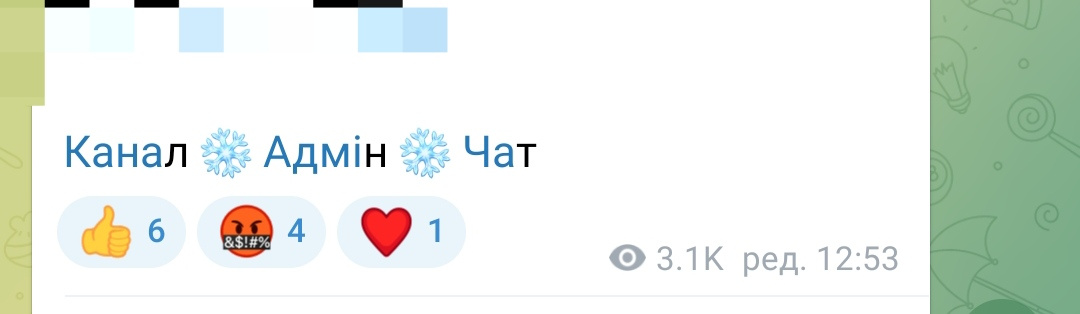
Готовый редактор постов канала, некорректно работает только если есть группа медиа и описание написано не к первому медиа)) В таком случае ссылки добавятся к первому медиа, но в следующем тоже будет описание, в итоге Телеграм не покажет ни одно. Но это исключение, лень фиксить.
from aiogram import Router, types, F
from aiogram.utils import formatting as fmt
# Редактор постов канала в отдельном роутере
router = Router()
# Это понадобится, чтобы в медиагруппе редактировалось только описание первого медиа
check_mg = set()
#Фильтры: проверим что пост не переслан и что это медиа имеющие caption
@router.channel_post(~F.forward_from_chat, ~F.forward_from, (F.text | F.photo | F.video | F.animation | F.document))
async def redactor(message: types.Message):
# Собираем текстовые данные из поста
text = message.text or message.caption or ''
# Собираем те entities которые уже есть в посте
ent = message.entities or message.caption_entities or []
# Удаляем встроенные ссылки если они есть
ent = [e for e in ent if e.type != 'text_link']
# Через инструмент formatting создаём внешний вид будущего поста
content = fmt.Text(
# Старый текст
text,
'\n\n',
# В моём случае я добавляю три ссылки на канал, чат и админа с эмодзи-разделителем
fmt.as_line(
fmt.Bold(fmt.TextLink("Канал", url='https://t.me/1')),
fmt.Bold(fmt.TextLink("Чат", url='https://t.me/2')),
fmt.Bold(fmt.TextLink("Админ", url='https://t.me/3')),
# Тут эмодзи который будет между ссылками
sep=' '
)
)
# Собираем новый текст и новые entities в кучу
text, new_ent = content.render()
# Тут расписывать не буду, разные проверки и разные варианты отправки отредактированного сообщения
if message.text is not None:
if len(text) <= 4096:
await message.edit_text(text, entities=ent + new_ent, disable_web_page_preview=True)
else:
print("Can't edit Text, length exceeded.")
elif message.media_group_id is None:
if len(text) <= 1024:
await message.edit_caption(caption=text, caption_entities=ent + new_ent, disable_web_page_preview=True)
else:
print("Can't edit Caption, length exceeded.")
elif message.media_group_id not in check_mg:
check_mg.add(message.media_group_id)
if len(text) <= 1024:
await message.edit_caption(caption=text, caption_entities=ent + new_ent, disable_web_page_preview=True)
await asyncio.sleep(1)
check_mg.remove(message.media_group_id)
else:
print("Can't edit Caption, length exceeded.")