Нужно написать код который парсит каталог товаров из интернет магазина на примере e-katalog и выгружает в таблицу .csv для дальнейшего импорта в WordPress WooCommerce, но это уже отдельная тема. Пока подключил библиотеки. При запуске кода создается .csv с заголовками, но информации по товарам нет. Код выглядит так:
import requests
import csv
import time
from lxml import html
from fake_headers import Headers
HEADERS = Headers(
browser="chrome",
os="win",
headers=True
).generate()
URL = 'https://www.e-katalog.ru/list/431/'
DOMAIN = 'https://www.e-katalog.ru'
ALL_DATA = dict()
QUEUE_URL = set()
def add_to_csv_from_file(product_dict):
with open('data.csv', 'a') as csvfile:
fieldnames = ["Name", "Price", "Url", "Title"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames,
quoting=csv.QUOTE_ALL)
writer.writerow(product_dict)
def get_data(product_link):
product = dict()
request = requests.get(product_link, headers=HEADERS)
tree = html.fromstring(request.content)
product_name = tree.xpath("//h1/text()")
product_price = tree.xpath("//div[@class='desc-short-prices'][1]//"
"div[@class='desc-big-price ib']//span[1]/text()")
product['Url'] = product_link
product['Title'] = tree.findtext('.//title')
for name in product_name:
product['Name'] = name
for price in product_price:
product['Price'] = price
time.sleep(3)
print('Сбор данных с URL', product_link)
return product
def get_links(page_url):
pagination_pages = set()
request = requests.get(page_url, headers=HEADERS)
tree = html.fromstring(request.content)
pages_count = tree.xpath('//div[@class="ib page-num"]//a[last()]/text()')
print('\nКод ответа корневого УРЛ:', request.status_code)
print('Всего страниц пейджинации:', pages_count)
for url in range(int(pages_count[0])):
full_url = f"https://www.e-katalog.ru/list/431/{url}/"
pagination_pages.add(full_url)
while len(pagination_pages) != 0:
current_url = pagination_pages.pop()
print('Сбор ссылок с URL:', current_url)
request = requests.get(current_url, headers=HEADERS)
tree = html.fromstring(request.content)
links = tree.xpath("//a[@class='model-short-title no-u']/@href")
for link in links:
QUEUE_URL.add(DOMAIN+link)
time.sleep(3)
def main():
with open('data.csv', 'a') as csvfile:
fieldnames = ["Name", "Price", "Url", "Title"]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames, quoting=csv.QUOTE_ALL)
writer.writeheader()
get_links(URL)
while len(QUEUE_URL) != 0:
current_url = QUEUE_URL.pop()
add_to_csv_from_file(get_data(current_url))
if __name__ == "__main__":
main()
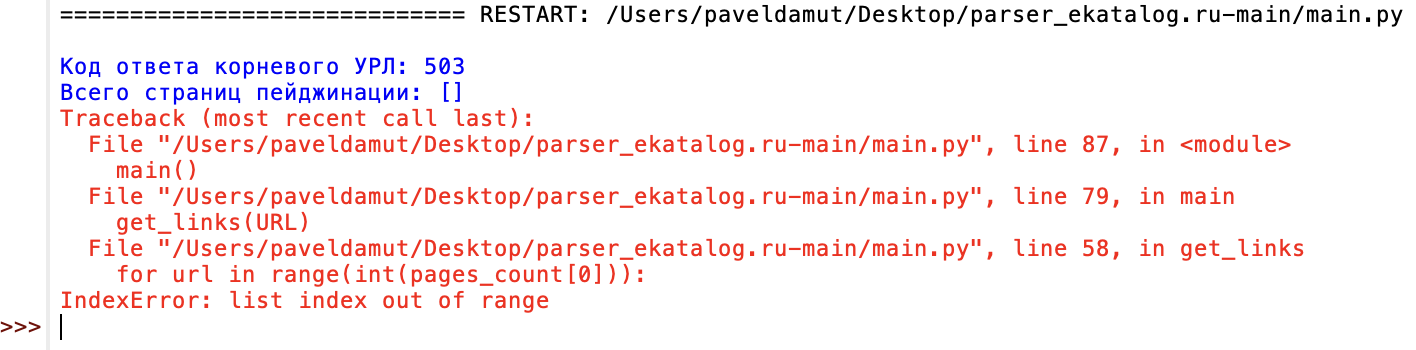
Так выглядит ошибка