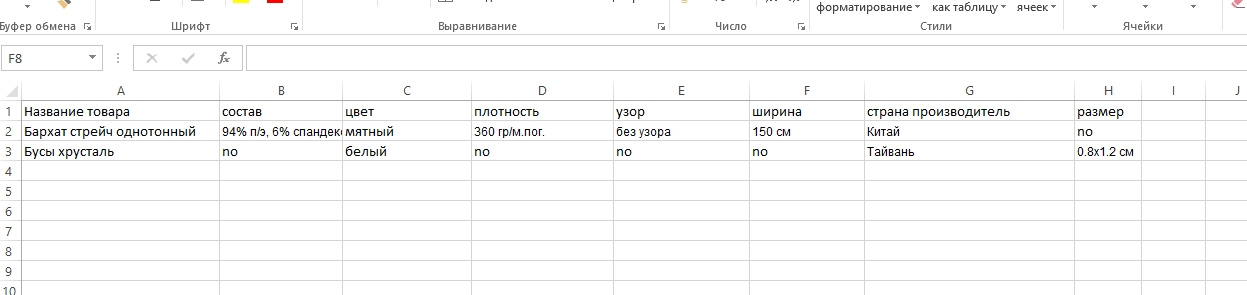
Недавно решал подобную задачу, при парсинге характеристик товаров, получал результирующий файл в Excel, где помимо общих данных товара: наименование, цена, описания, картинки и т.д., все характеристики были разнесены по разным колонкам, как то так:

Для получения данных с сайта источника, тоже использовал библиотеку
BeautifulSoup,
Фрагмент HTML кода с характеристиками товара на сайте источнике для парсинга:
<div id="content_features" class="ty-wysiwyg-content content-features">
<div class="ty-product-feature">
<div class="ty-product-feature__label">Ширина:</div>
<div class="ty-product-feature__value">1400<span class="ty-product-feature__suffix"> мм</span></div>
</div>
<div class="ty-product-feature">
<div class="ty-product-feature__label">Высота:</div>
<div class="ty-product-feature__value">1345<span class="ty-product-feature__suffix"> мм</span></div>
</div>
<div class="ty-product-feature">
<div class="ty-product-feature__label">Глубина:</div>
<div class="ty-product-feature__value">880<span class="ty-product-feature__suffix"> мм</span></div>
</div>
</div>
Фрагмент кода получения характеристик товара:
propsBody = []
try:
propsBody = soup.find('div', {'id' : 'content_features'}).findAll('div', class_='ty-product-feature')
except:
pass
if len(propsBody) > 0:
#self.properties.clear()
propsItems = []
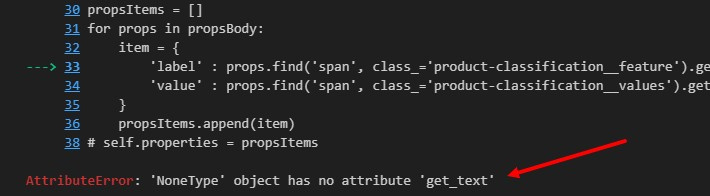
for props in propsBody:
item = {
'label' : props.find('div', class_='ty-product-feature__label').get_text(strip=True),
'value' : props.find('div', class_='ty-product-feature__value').get_text(strip=True)
}
propsItems.append(item)
self.properties = propsItems
В результате, полученные данные характеристик, для каждого товара в виде словаря, типа:
[{"label": "Высота:", "value": "220мм"},
{"label": "Глубина:", "value": "295мм"},
{"label": "Материал:", "value": "Сталь"},
{"label": "Вес:", "value": "4,3кг"},
{"label": "Длина:", "value": "650мм"}]
Где в label - название характеристики, а в value – значение.
Учитывая, что у всех товаров разные типы, названия характеристик, собирал их в множество – так как в множестве могут быть только уникальные значения. Затем, при записи данных в Excel, как предлагал выше
shurshur, автоматически добавлял колонки из полученных данных.
Вот пример класса, который принимает полученные в результате парсинга данные товаров, и записывает их Excel.
В данном прмере Вы можете увидеть, что помимо общих полей – для данных товара, как название, цена, описание и т.д, из названий характеристик в цикле добавляются колонки, куда записываются значения характеристик товара:
spoiler
class ExcelFile:
data = {}
labels = set() # множество, перменная, свойство для названий характеристик товаров
def __init__(self, data):
self.data = data
def get(self):
# В цикле проходим по данным полученным в результате парсинга,
# и собираем названия характеристик в множество
for item in self.data:
if len(item['properties']) > 0:
for prop in item['properties']:
self.labels.add(prop['label'])
book = openpyxl.Workbook()
sheet = book.active
# Поля, колонки Excel - файла, для разных данных товаров
sheet['A1'].value = 'src'
sheet['B1'].value = 'name'
sheet['C1'].value = 'category'
sheet['D1'].value = 'art_namber'
sheet['E1'].value = 'price'
sheet['F1'].value = 'main'
sheet['G1'].value = 'more'
sheet['H1'].value = 'descrip'
sheet['I1'].value = 'JSON_properties'
sheet['J1'].value = 'video'
sheet['K1'].value = 'docs'
# Добавляем дополнительные колонки в Excel из названий характеристик
if len(self.labels) > 0:
nam = 12
for nameProp in self.labels:
sheet.cell(row=1, column=nam, value=nameProp)
nam += 1
row = 2
# Записываем в строки Excel- файла данные товаров
for res in self.data:
sheet[row][0].value = res['src']
sheet[row][1].value = res['name']
sheet[row][2].value = res['category']
sheet[row][3].value = res['art_namber']
sheet[row][4].value = res['price']
sheet[row][5].value = res['main']
sheet[row][6].value = ','.join(res['more'])
sheet[row][7].value = res['descrip']
sheet[row][8].value = res['json']
sheet[row][9].value = ','.join(res['video'])
sheet[row][10].value = ','.join(res['docs'])
# Записываем значения характеристик товара в соответствующие названиям колонки Excel- файла
if len(self.labels) > 0:
namberCell = 12
while namberCell < len(self.labels) + 12:
propLabel = sheet.cell(row=1, column=namberCell).value
for property in res['properties']:
if property['label'] == propLabel:
sheet.cell(row=row, column=namberCell).value = property['value']
else:
sheet.cell(row=row, column=namberCell)
namberCell += 1
row += 1
file_name = detNameExcelFile()
book.save(file_name)
book.close()
return file_name
Возможно, данную задачу можно решить другим, более рациональным способом, но тем не менее -это способ работает.