
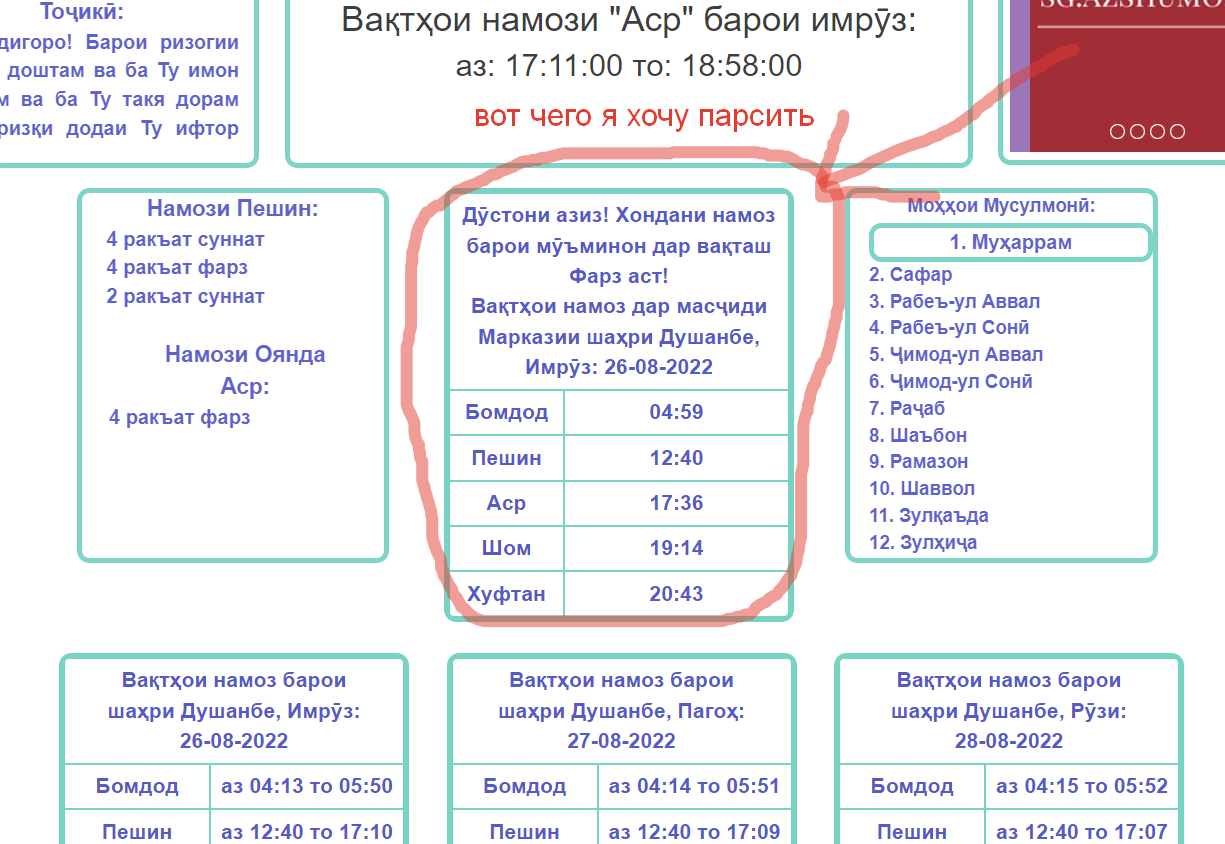
import Beautifulsoup as BS
import requests
r = requests.get('http://takvim.tj/')
soup = BS(r.content, 'lxml')
 Простой
Простой
Простой
Простой

