Есть приложение, задача которого - сделать поиск по запросу пользователя. Порядок действий примерно следующий: запрос пользователя -> запрос к различным API -> получение результатов от API -> сохранение в БД -> обработка данных -> ответ пользователю. Работать такой поиск должен быстро (в пределах 15-20 сек).
На один запрос пользователя предполагается сделать 200+ запросов к API с различными параметрами.
Сейчас для поиска создаются 200 потоков, которые выполняют запросы к API и пишут в базу. Проблема в том, что такое решение выглядит очень ограниченно - если прийдет еще один пользователь и сделает поиск, будет создано еще 200+ потоков и время ответа существенно снизится.
Смотрю в сторону использования Sidekiq, RabbitMQ, чтобы была возможность добавлять поисковые сервера и распараллеливания поиска (например, каждый сервер выполняет запросы с разными параметрами), но терзают сомнения - как быть с MySQL? Не будет ли проблемы с max_connections, если несколько серверов будут писать в одну базу? Какие еще решения можно рассмотреть, чтобы была возможность распараллеливания поиска, и по окончанию работы всех получить событие "поиск закончен", чтобы обработать данные?
Приложение - Rails, БД - MySQL.
Самое универсальное решение - это конечно очередь заданий. Не увлекайтесь созданием коннектов к БД. Лучше иметь немного коннектов, но которые работают быстро, чем кучу - но которые работают медленно.
На крайняк, всегда можно написать решение (аля на Erlang), которое будет брать работу по распараллеливанию на себя, вам нужно лишь будет вызвать нужный http-api такого сервера и получить ответ.
Чтобы БД работала быстро, можно поставить кучу mysql slave серверов, и обращаться также к ним. Писать конечно получится только на один. А вообще все зависит от вашей задачи. У вас скупое описание того, что вы хотите делать и для чего.
Задача - запрос наличия жилья у разных партнеров по разным параметрам. Например, есть 5 партнеров и 40 параметров (объединить в 1 запрос не представляется возможным). Т.е. на данный момент - 1 параметр к 1 партнеру = 1 поток (он же 1 коннект к базе). После сбора всех данных производится обработка (фильтрация, поиск лучших вариантов). Собственно, для обработки все результаты и пишутся в базу.
С выборкой данных проблем нет, только с записью.
Идея интересная.. но результаты 200 потоков тоже надо где-то сохранять временно, пока последний не запишет все в базу. В моем случае каждый поток может вернуть что-то вроде сериализованного массива.
ну вы же для пользователя создаете поток, который отдает какой то результ пользователю после отработки 200 запросов ... почему не собирать результаты в нем, и в нем же записывать что и куда надо .. а еще лучше все класть в очередь заданий, и воркерами записывать.
черт.. а решение-то было близко :) спасибо за наводку - действительно, перекладывать результат выполнения 200 потоков в очередь, чтобы только воркер писал в базу выглядит наиболее красивым решением.
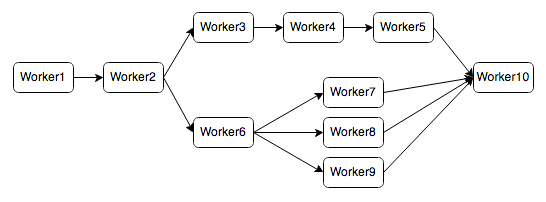
Можете подсказать, как с помощью RabbitMQ реализовать такую схему: https://raw.githubusercontent.com/socialpandas/sid...
т.е. Worker6 генерирует для Worker7,8,9 задачи и 10 начинает работать только после завершения работы предыдущих?




{kind=link}