Как правильно парсить страницу, что бы брать с нее информацию?
Добрый день.
Есть задача брать с определенной страницы информацию и загонять ее общую базу: количество и цену товара. В виду своей неопытности в парсинге сайтов, при просмотре кода страницы через браузер нужных цены и количества нет, но при исследовании элемента страницы эта информация есть. При парсинге я же буду получать весь код страницы где нет нужной мне информации.
Подскажите пожалуйста, о чем я не знаю или что не понимаю?
Парсер хочу писать на C#
Парсить сайт буду не часто - раз в 4 часа, так что проверку в виде капчи получить не должен.
alexbprofit, подскажите пожалуйста один момент, ибо в html языке не силен) Элемент в коде страницы чем является?
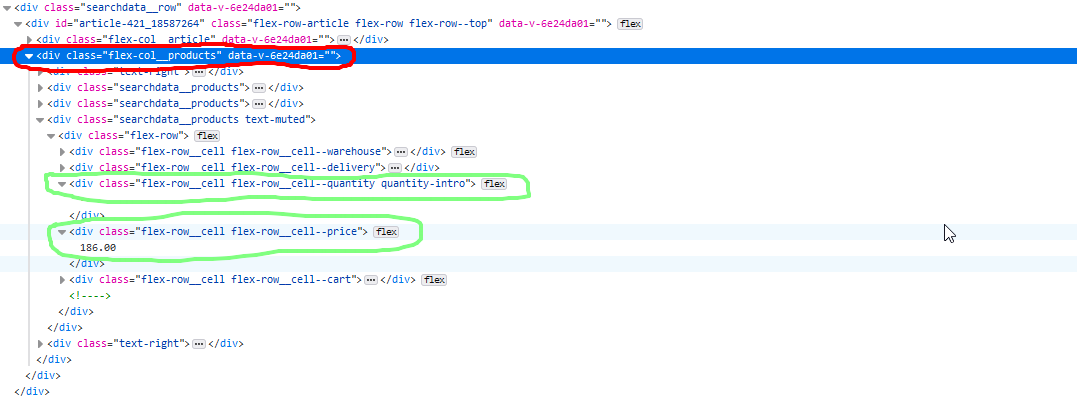
Вот пример элемента из нужной мне страницы:
Красным - основной элемент в котором хранятся нужные данные
Зеленым - элементы, которые нужно достать для базы

 Простой
Простой