import nltk
nltk.download()
name = input('Please, put your surname, name, group and number of Lab:')
a = name
print(a)
from nltk.corpus import wordnet as wn
for synset in wn.synsets('journal', wn.NOUN):
print(synset.name() + ':', synset.definition())
for synset in wn.synsets('blog', wn.NOUN):
print(synset.name() + ':', synset.definition())
print(wn.synset('diary.n.01').hypernyms())
print(wn.synset('journal.n.02').hypernyms())
print(wn.synset('daybook.n.01').hypernyms())
print(wn.synset('journal.n.04').hypernyms())
print(wn.synset('journal.n.05').hypernyms())
print(wn.synset('web_log.n.01').hypernyms())
print(wn.synset('diary.n.01').hyponyms())
print(wn.synset('journal.n.02').hyponyms())
print(wn.synset('daybook.n.01').hyponyms())
print(wn.synset('journal.n.04').hyponyms())
print(wn.synset('journal.n.05').hyponyms())
print(wn.synset('web_log.n.01').hyponyms())
diary = wn.synset('diary.n.01')
journal = wn.synset('journal.n.02')
daybook = wn.synset('daybook.n.01')
web_log = wn.synset('web_log.n.01')
print('diary:', diary.min_depth())
print('journal:', journal.min_depth())
print('daybook:', daybook.min_depth())
print('web_log:', web_log.min_depth())
print(journal.lowest_common_hypernyms(diary))
print(journal.lowest_common_hypernyms(daybook))
print(journal.lowest_common_hypernyms(web_log))
print(journal.path_similarity(journal))
print(journal.path_similarity(diary))
print(journal.path_similarity(daybook))
print(journal.path_similarity(web_log))
#Wu-Palmer Similarity
print(journal.wup_similarity(daybook))
print(journal.wup_similarity(web_log))
print(journal.lch_similarity(daybook))
print(journal.lch_similarity(web_log))
def levenshtein(s1, s2):
d = {}
s1_length = len(s1)
s2_length = len(s2)
for i in range(-1, s1_length + 1):
d[(i,-1)] = i + 1
for j in range(-1, s2_length + 1):
d[(-1, j)] = j + 1
for i in range(s1_length):
for j in range(s2_length):
if s1[i] == s2[j]:
cost = 0
else:
cost = 1
d[(i, j)] = min(
d[(i - 1, j)] + 1,
d[(i, j - 1)] + 1,
d[(i - 1, j - 1)] + cost,
)
return d[s1_length - 1, s2_length - 1]
word1 = 'blog'
word2 = 'journal'
d1 = levenshtein(word1, word2)
print(f"Result for'{word1}' & '{word2}' :", d1)
import nltk
nltk.download()
name = input('Please, put your surname, name, group and number of Lab:')
a = name
print(a)
from nltk.corpus import wordnet as wn
for synset in wn.synsets('journal', wn.NOUN):
print(synset.name() + ':', synset.definition())
for synset in wn.synsets('blog', wn.NOUN):
print(synset.name() + ':', synset.definition())
print(wn.synset('diary.n.01').hypernyms())
print(wn.synset('journal.n.02').hypernyms())
print(wn.synset('daybook.n.01').hypernyms())
print(wn.synset('journal.n.04').hypernyms())
print(wn.synset('journal.n.05').hypernyms())
print(wn.synset('web_log.n.01').hypernyms())
print(wn.synset('diary.n.01').hyponyms())
print(wn.synset('journal.n.02').hyponyms())
print(wn.synset('daybook.n.01').hyponyms())
print(wn.synset('journal.n.04').hyponyms())
print(wn.synset('journal.n.05').hyponyms())
print(wn.synset('web_log.n.01').hyponyms())
diary = wn.synset('diary.n.01')
journal = wn.synset('journal.n.02')
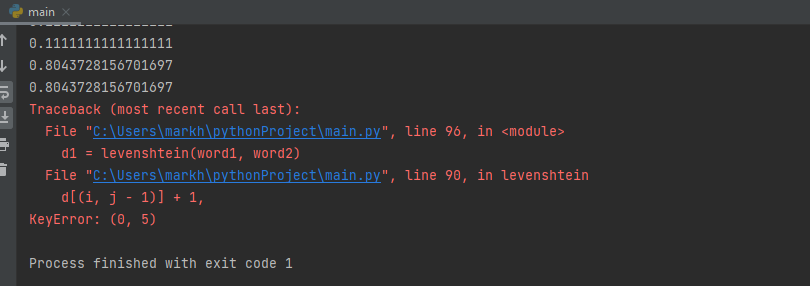
daybook = wn.synset('daybook.n.01')
web_log = wn.synset('web_log.n.01')
print('diary:', diary.min_depth())
print('journal:', journal.min_depth())
print('daybook:', daybook.min_depth())
print('web_log:', web_log.min_depth())
print(journal.lowest_common_hypernyms(diary))
print(journal.lowest_common_hypernyms(daybook))
print(journal.lowest_common_hypernyms(web_log))
print(journal.path_similarity(journal))
print(journal.path_similarity(diary))
print(journal.path_similarity(daybook))
print(journal.path_similarity(web_log))
#Wu-Palmer Similarity
print(journal.wup_similarity(daybook))
print(journal.wup_similarity(web_log))
print(journal.lch_similarity(daybook))
print(journal.lch_similarity(web_log))
def levenshtein(s1, s2):
d = {}
s1_length = len(s1)
s2_length = len(s2)
for i in range(-1, s1_length + 1):
d[(i,-1)] = i + 1
for j in range(-1, s2_length + 1):
d[(-1, j)] = j + 1
for i in range(s1_length):
for j in range(s2_length):
if s1[i] == s2[j]:
cost = 0
else:
cost = 1
d[(i, j)] = min(
d[(i - 1, j)] + 1,
d[(i, j - 1)] + 1,
d[(i - 1, j - 1)] + cost,
)
if i and j and s1[i]==s2[j-1] and s1[i-1] == s2[j]:
d[(i,j)] = min (d[(i,j)], d[i-2,j-2] + 1)
return d[s1_length - 1, s2_length - 1]
word1 = 'blog'
word2 = 'journal'
d1 = levenshtein(word1, word2)
print(f"Result for '{word1}' & '{word2}' :", d1) Средний
Простой
Сложный
Средний
Средний
Простой
Сложный
Средний