Здравствуйте, довольно долго сижу над проблемой, туториалы не помогают, а подходящих ответов в интернете не нашел.
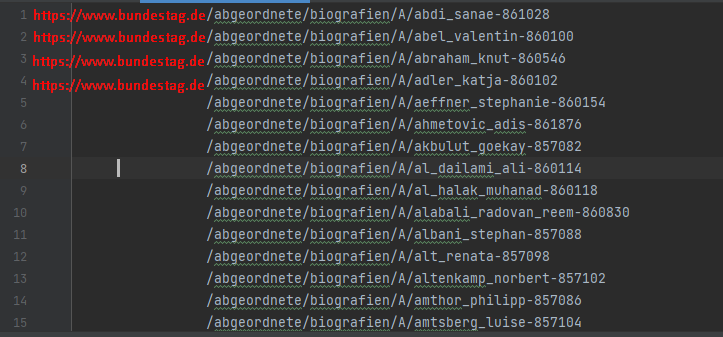
В общем выгружаю список ссылок, но в атрибуте href указано лишь половина ссылки для каждой позиции в списке вначале не хватает части
https://www.bundestag.de
Перепробовал все методы работы со списками, которые нашел, но не догоняю как вставить (слепить) в каждое значение необходимый элемент, думаю задача простая, но меня поставила в тупик(
persons_url_list = []
for i in range(0, 740, 20):
url =f"https://www.bundestag.de/ajax/filterlist/de/abgeordnete/862712-862712?limit=20&noFilterSet=true&offset={i}"
q = requests.get(url)
result = q.content
soup = BeautifulSoup(result, 'lxml')
persons = soup.find_all(class_="bt-open-in-overlay")
for person in persons:
person_page_url = person.get('href')
persons_url_list.append(person_page_url)
with open('persons_url_list.txt', 'a') as file:
for line in persons_url_list:
file.write(f'{line}\n')
пример одной из ссылок, которая должна быть в списке
https://www.bundestag.de/abgeordnete/biografien/A/...