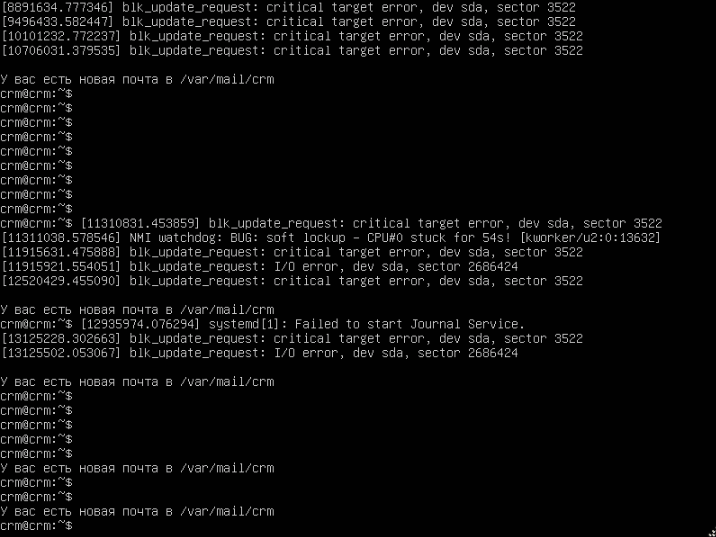
В первую очередь сделайте копию всех важных данных на сервере и убедитесь, что в копии они не повреждены.
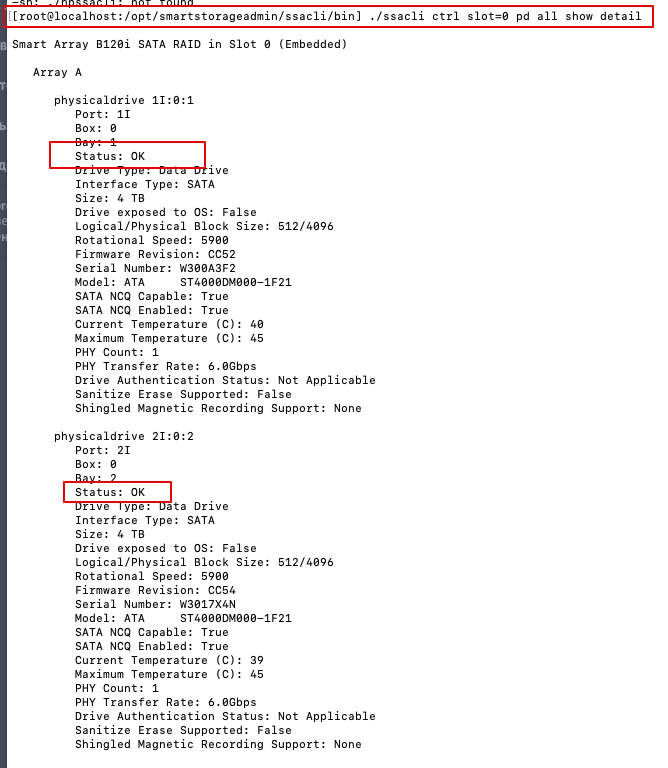
развернут ESXI 6.5 ... Диски работают в RAID 1+0 под контроллером HP b120i
ESXI и RAID-контроллер - это действительно, два "слоя", которые могут помешать взаимодействию с дисками напрямую. Как минимум, с рэйд-контроллером надо изучать как работает он сам, что позволяют его драйверы, и какой софт доступен.
Если не получится пробиться в родной ОС, то пронумеруйте диски, разберите массив, и подключите диски напрямую к компьютеру с Виндоус. Windows давно стала отраслевым стандартом в data recovery и весь самый интересный софт разрабатывается под неё, независимо от того, с какими накопителями ведётся работа. Если она предложит инициализировать/форматировать диски, или запустит проверку - откажитесь / остановите.
Скачайте и распакуйте R.tester:
https://rlab.ru/tools/rtester.html
В нём можно как посмотреть SMART, так и сделать максимально детальные тесты чтения, которые покажут состояние поверхности.
Можно также сделать тесты записи, но они уничтожают всё безвозвратно, так что предварительно надо готовиться (бэкапить данные или делать образы дисков).


 Простой
Простой
 Простой
Простой
 Простой
Простой
 Простой
Простой