а на счет того зачем у меня есть parser и когда ему пытаешься скормить этот файл в кодировке utf-8 он не может прочитать файл все время находить неизвестные символы и да можно попробовать взять не большой кусок файла и тогда он корректно отработает но все русские символы будут в таком виде Øèêè, òû âñ¸ íå óõîäèë äîìî
Я также попробовал открыть этот кусок файла с помощью win1251 и тогда он отработал корректно и не шакалил ни русские ни японские символы все было замечательно но когда пытался сделать тоже самое со всем файлом он выдавал ошибку
UnicodeDecodeError: 'charmap' codec can't decode byte 0x98 in position 248964: character maps to
И вот я подумал что нужно перекодировать файл в windows-1251
Алан Гибизов, Первое я ничего не разрабатываю я просто пытаюсь заставить работать старый код который откопал на github
Второе По моему такой метод обучение очень даже
эффективен
по крайне мере я так учу языки подумал что и к языками программирования такой метод потходит
не зубрить теорию а взять готовый матириал и по кусочкам разбирать его.
Извините если в среде программирования такое не приветствуется я как вы уже понили новичок и не знаю что можно а что нелзя
Алан Гибизов, Я постил сюда вопрос и сам одновременно искал решение и как только находил решение для одной проблемы за ней повалялась другая сначала пробовал сам потом постил сюда и потом находил ответ потом новая проблема и так далее Разве это преступление ?
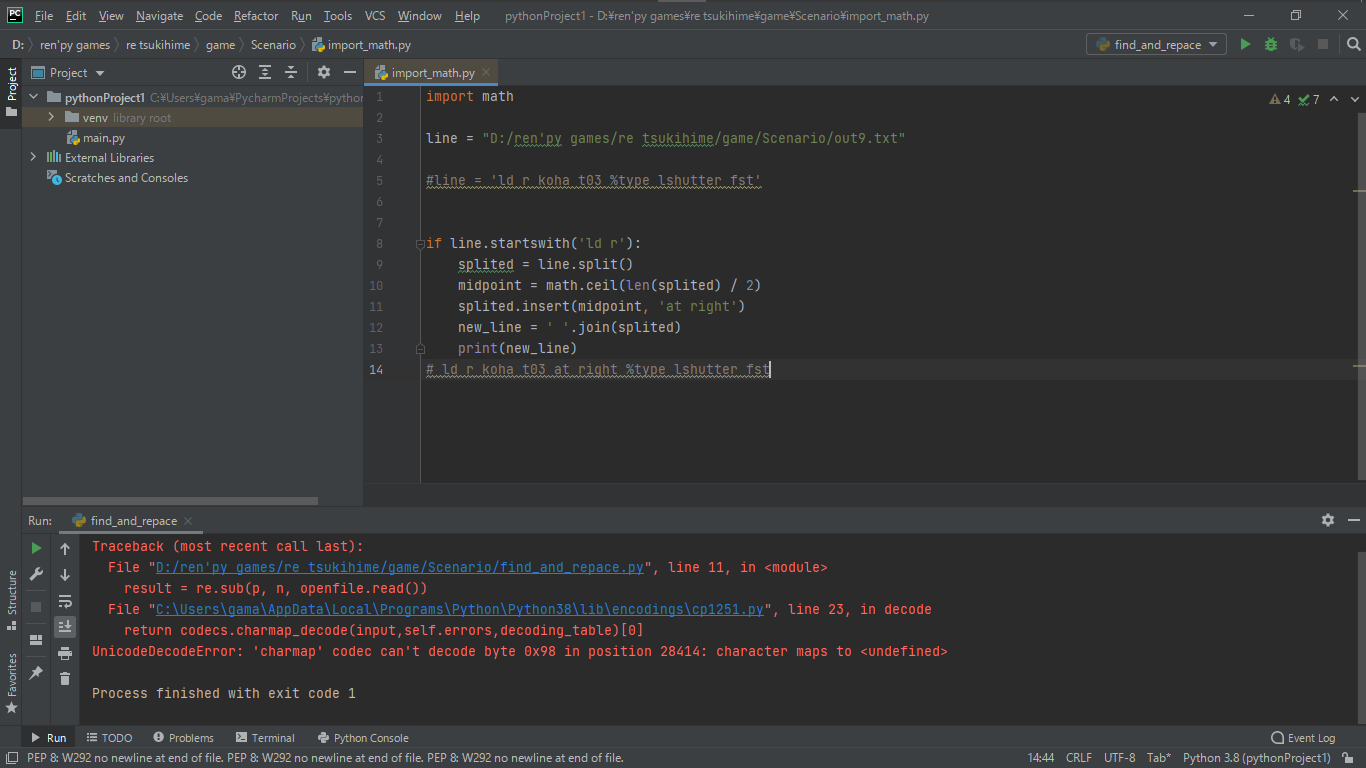
Evgeniy _, Если сделать это так у меня выводить
D:\ren'py games\Retsukihime2\game\nscripter2renpy-master\src>python nscripter2renpy.py script.txt > script.rpy
Traceback (most recent call last):
File "nscripter2renpy.py", line 35, in
content = parser.read_script(input)
File "D:\ren'py games\Retsukihime2\game\nscripter2renpy-master\src\parsar.py", line 67, in read_script
val = ord(c)
TypeError: ord() expected string of length 1, but int found
yupiter7575, Я проверял его там нет и я не знаю что это за файл судя по названию это что то и библиотеки логов но гугл нечего мне не выдал вот я подумал может дело в другом
Сергей Карбивничий, на счет первого код в низу картинки я вставил картинку для того что бы было визуально лучше видно а на счет второго вроде в правилах такого не было простите если не внимательно прочитал так куда мне выложит файлом ?
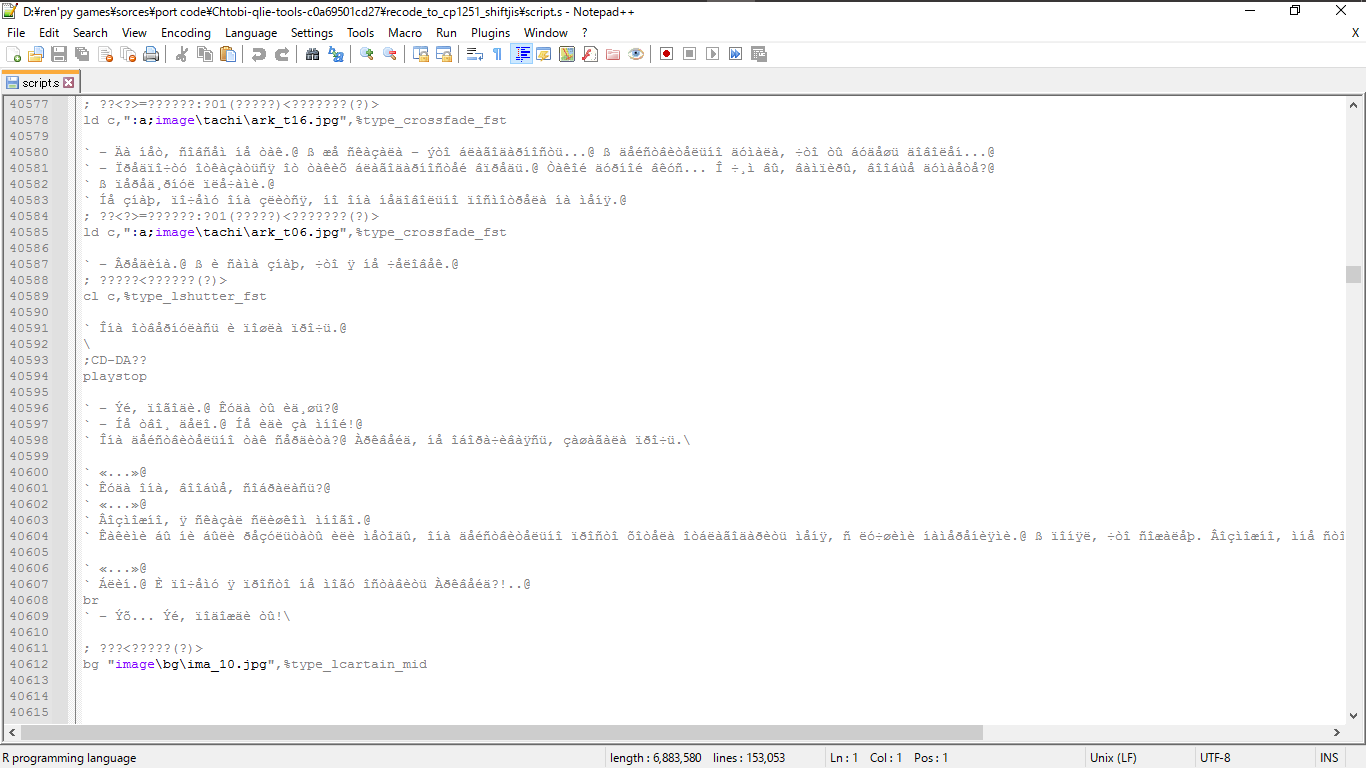

а на счет того зачем у меня есть parser и когда ему пытаешься скормить этот файл в кодировке utf-8 он не может прочитать файл все время находить неизвестные символы и да можно попробовать взять не большой кусок файла и тогда он корректно отработает но все русские символы будут в таком виде Øèêè, òû âñ¸ íå óõîäèë äîìî
Я также попробовал открыть этот кусок файла с помощью win1251 и тогда он отработал корректно и не шакалил ни русские ни японские символы все было замечательно но когда пытался сделать тоже самое со всем файлом он выдавал ошибку
UnicodeDecodeError: 'charmap' codec can't decode byte 0x98 in position 248964: character maps to
И вот я подумал что нужно перекодировать файл в windows-1251