ага, вот нашёл примерный ответ), т.е. нужно на сервере установить virtualenv со всем необходимым а потом на крон поставить вот это?
#!/bin/bash
#заходим в папку с окружением
cd '/path/to/spider/activate'
# активируем
source venv/bin/activate
#заходим в папку с парсером
cd '/path/to/spider/my_spider_1'
# запускаем парсер
scrapy crawl my_spider_1
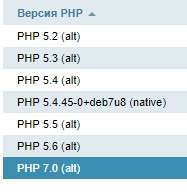
IceJOKER, а ещё такой вопрос если у меня проект на php 7 на сервере основным показывает 5.4 но 7 тоже есть
то оно все равно будет выдавать ошибку? и для меня единственное решение это будет использовать docker?
Astrohas, покопался и понял что у меня первым срабатывает pipelines.py а middlewares.py нет, но разве так должно быть?, у меня ж данные о подключении в middlewares.py и сначала должен сработать connect чтобы потом можно было работать дальше, и если мы сделаем подключение в pipelines то у нас connect будет срабатывать каждый раз , или я не понимаю что-то?)
Astrohas: а что может вызывать эту ошибку?
AttributeError: 'CraigslistPipeline' object has no attribute 'cursor'
доступы к базе все рабочие, проверил вот так
import mysql.connector
mysql.connector.connect(host='host', database='database', user='user', password='password', charset='utf8', use_unicode=True)


я правильно понял?)