

let str = 'Слово';
str.match(/[ауоыиэяюёе]/ig).length;
// 2//-------------------------------------// variant 0
var str = 'Пользователь задает слова и нужно найти слово, которое содержит наибольшее количество гласных букв через регулярные выражение';
var words = str.split(' ');
var wordLength = [];
words.forEach(word => wordLength.push([word.length, word]));
var maxWord = wordLength.sort((a, b) => b[0]-a[0]).slice(0, 1)[0][1];
// variant 1
var str = 'Пользователь задает слова и нужно найти слово, которое содержит наибольшее количество гласных букв через регулярные выражение';
var words = str.split(' ');
var wordLength = {};
words.forEach(function(word){
wordLength[word.length] = wordLength[word.length] || [];
wordLength[word.length].push(word);
});
var maxWords = wordLength[Object.keys(wordLength).sort((a, b) => Math.max(a,b)).shift()];Единственное только, если расширить до 254 диапазон. Это не ограничится же только измеение последней цифры на с 220 на 254?
1\.1\.1\.(?:19[1-9]|2[0-4]\d|25[0-4])
$str = 'текст ДПБ02 текст еще';
echo $str . PHP_EOL;
if (preg_match_all('/([А-Я]*)(\d*)/iu', $str, $matches, PREG_SET_ORDER)) {
foreach ($matches as $index => $match) {
if (count(array_filter($match))) {
echo '#' . $index . ' ' . $match['1'] . ' ' . $match['2'] . PHP_EOL;
}
}
}let counter = 0;
let $form = $('div.form');
$form.on('click', 'input.clone-row', function(){
let $self = $(this);
let cloneRow = $self.parent().clone();
counter++;
cloneRow.find('input.form-control').each(function(i, input){
let $input = $(input);
let inputName = $input.attr('name');
let newName = inputName.replace(/(.*?\[)\d+(\].*)/i, '$1' + counter + '$2');
$input.attr('name', newName);
$input.val(newName); // это, конечно же, можно (нужно) убрать. здесь только для наглядности
});
$form.append(cloneRow);
});Почему не удается использовать такую конструкцию ?(?<=https?).*
https? получается либо 5 (https), либо 4 (http)(?<=https|http).*https?.*
Для меня по логике перед loohahead должны быть символы
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*\d) - обязательно впереди от начала строки должна быть хотябы 1 цифра, не важно в каком именно месте.*, где . - любой символ и и квантор * 0 или "много" раз, а потом цифра \d(?=.*[a-z]) - обязательно 1 маленькая буква латинского алфавита(?=.*[A-Z]) - обязательно 1 большая буква латинского алфавитаИ второй вопрос. Почему этот регэксп работает в случае если меняешь местами такие символы:
abC123, Cab123, 123Cab - то есть порядок прописных строчных и цифр не важен, но ведь группы lookahead идут по порядку
(?=.*\d)(?=.*[a-z])(?=.*[A-Z]) после слова пример-
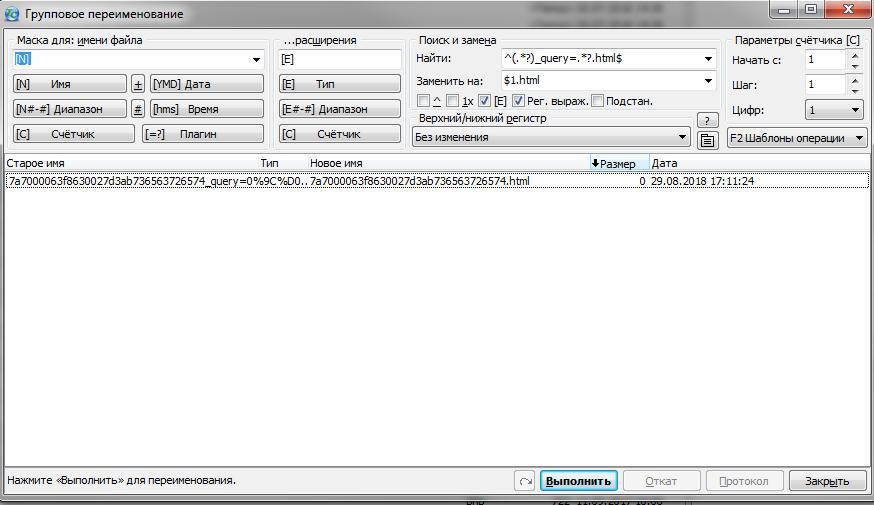
^(.*?)_query=.*?.html$$1.html
/(\b[^\s]+\b)(?!([^\[]*\]))/g
Если я правильно понимаю, то вторая группа фильтрует первую
(?!([^\[]*\]))По аналогии я пытаюсь добавить его третьей группой с negative lookagead, чтобы первая группа искала все слова, вторая удаляла оттуда всё, что в скобках, а третья убирала ссылки. Получается/(\b[^\s]+\b)(?!([^\[]*\]))(?!(\bhttp[^\s]+\b))/g
Составил выражение (?<=/icons\/).*\.png(?<=/icons\/).*?\.png
let words = ['набор', 'определенных', 'слов'];
let Reg = new RegExp(words.map(word => `.*(?=${word})`).join(''), 'i');
let text1 = 'какойто текст и набор определенных слов';
let text2 = 'какойто текст определенных слов';
Reg.test(text1);
// true
Reg.test(text2);
// false
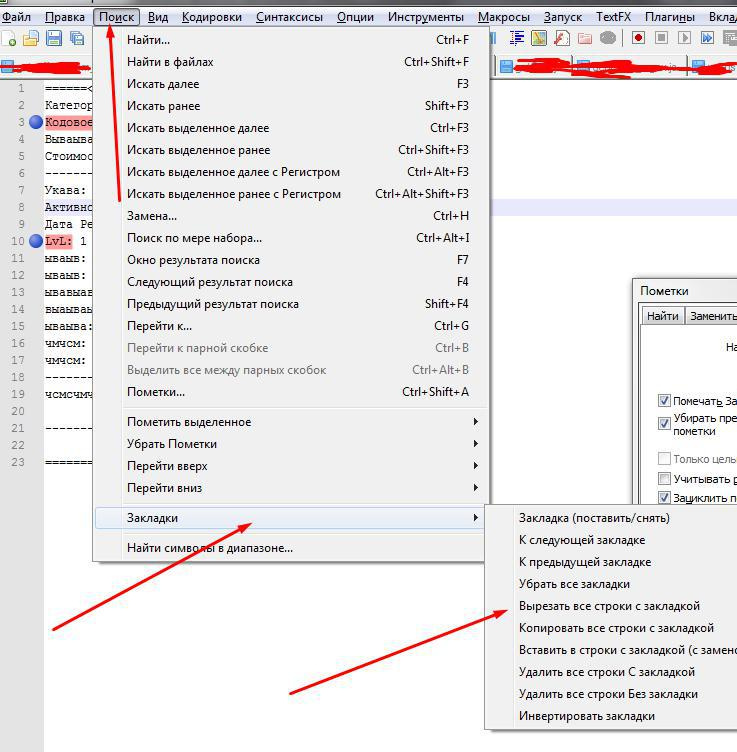
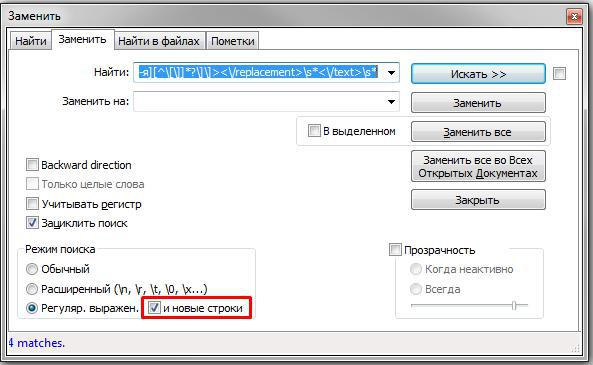
Вопрос 2: в базе DLE хранит "url" якобы в поле "alt_name", но не полностью )) на выходе url выглядит как поле "id-"+поле "alt_name"+".html"
т.е. в данном примере итоговый url выглядит 39-lekciya-tayshi-abelyar-1994g.html, а в поле alt_name хранится только lekciya-tayshi-abelyar-1994g
(\(\d+, '[^'<>]*?)<\/?[^<>]*>$1