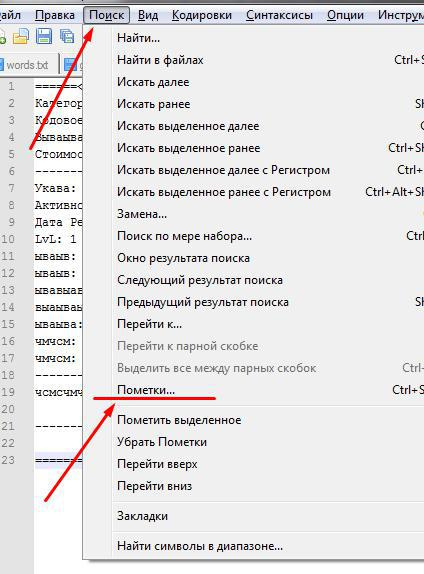
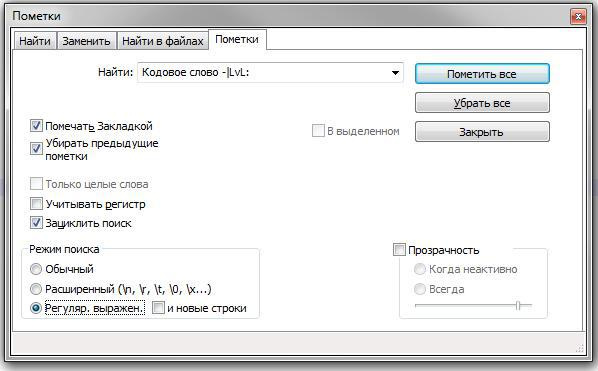
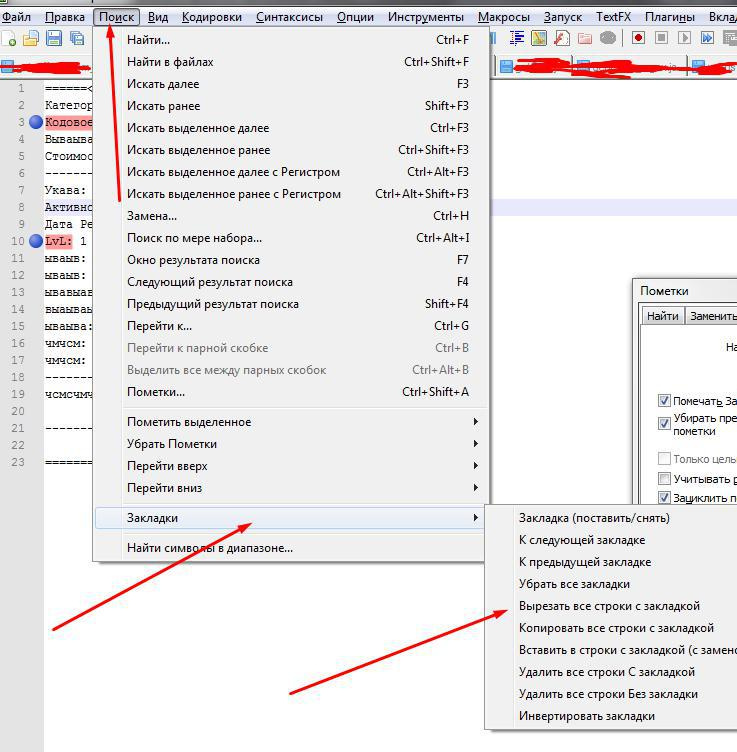
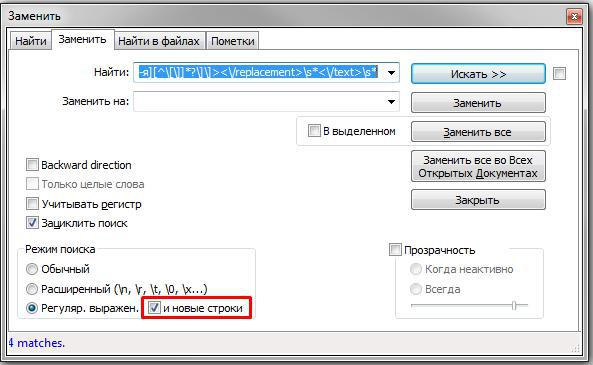
$track->href$track->attr('href');
$track->getAttribute('href');foreach($r_div as $div) { $track=$div->find('a[class="track-more-info"]'); }
$track получается массив с найденными элементами a[class="track-more-info"]foreach ($track as $item) {
echo $item->href;
}$list = $div->find('a[class="track-more-info"]');
$track = array_shift($list);
if (!empty($track)) {
echo $track->href;
}$str = 'текст ДПБ02 текст еще';
echo $str . PHP_EOL;
if (preg_match_all('/([А-Я]*)(\d*)/iu', $str, $matches, PREG_SET_ORDER)) {
foreach ($matches as $index => $match) {
if (count(array_filter($match))) {
echo '#' . $index . ' ' . $match['1'] . ' ' . $match['2'] . PHP_EOL;
}
}
}let counter = 0;
let $form = $('div.form');
$form.on('click', 'input.clone-row', function(){
let $self = $(this);
let cloneRow = $self.parent().clone();
counter++;
cloneRow.find('input.form-control').each(function(i, input){
let $input = $(input);
let inputName = $input.attr('name');
let newName = inputName.replace(/(.*?\[)\d+(\].*)/i, '$1' + counter + '$2');
$input.attr('name', newName);
$input.val(newName); // это, конечно же, можно (нужно) убрать. здесь только для наглядности
});
$form.append(cloneRow);
});$array1 = preg_match_all('/"(.*?)"/i', $ro, $match) !== false ? $match[1] : [];$str = 'кактвоидела';
$variants = [];
$len = mb_strlen($str);
for ($i = 0; $i < $len; $i++) {
for ($n = 0; $n < $len; $n++) {
$v = mb_substr($str, $i, $n);
if (mb_strlen($v) > 1) {
$variants[] = $v;
}
}
}
// убираем дубли
$variants = array_unique($variants);Почему не удается использовать такую конструкцию ?(?<=https?).*
https? получается либо 5 (https), либо 4 (http)(?<=https|http).*https?.*
Для меня по логике перед loohahead должны быть символы
^(?=.*\d)(?=.*[a-z])(?=.*[A-Z])(?=.*\d) - обязательно впереди от начала строки должна быть хотябы 1 цифра, не важно в каком именно месте.*, где . - любой символ и и квантор * 0 или "много" раз, а потом цифра \d(?=.*[a-z]) - обязательно 1 маленькая буква латинского алфавита(?=.*[A-Z]) - обязательно 1 большая буква латинского алфавитаИ второй вопрос. Почему этот регэксп работает в случае если меняешь местами такие символы:
abC123, Cab123, 123Cab - то есть порядок прописных строчных и цифр не важен, но ведь группы lookahead идут по порядку
(?=.*\d)(?=.*[a-z])(?=.*[A-Z]) после слова пример-
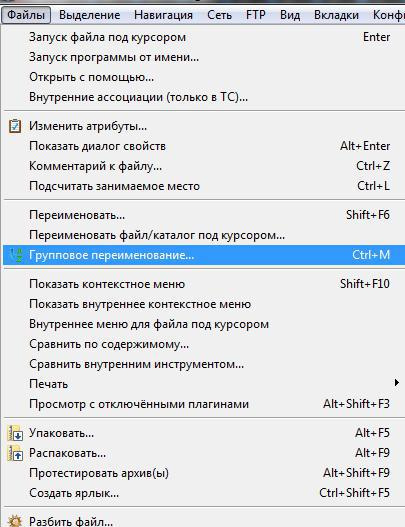
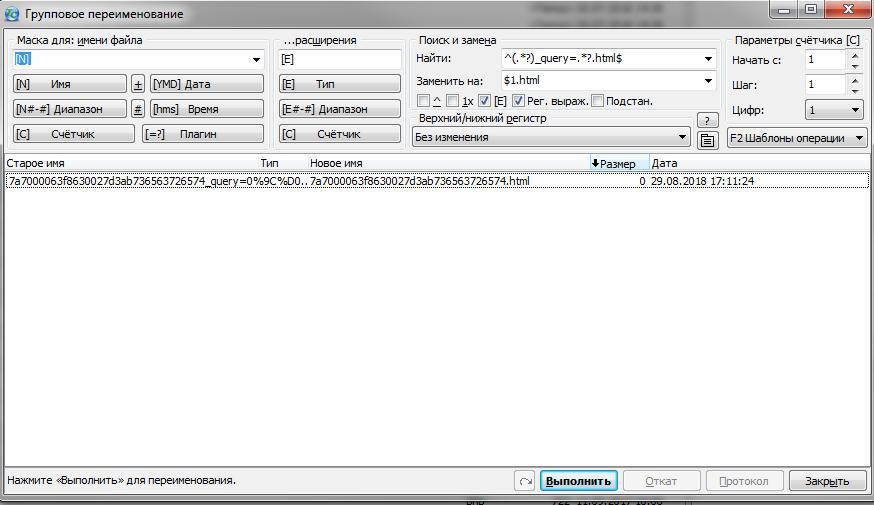
^(.*?)_query=.*?.html$$1.html
curl_setopt($curl, CURLOPT_URL, 'https://'.$url;curl_setopt($curl, CURLOPT_URL, 'https://' . $url);/(\b[^\s]+\b)(?!([^\[]*\]))/g
Если я правильно понимаю, то вторая группа фильтрует первую
(?!([^\[]*\]))По аналогии я пытаюсь добавить его третьей группой с negative lookagead, чтобы первая группа искала все слова, вторая удаляла оттуда всё, что в скобках, а третья убирала ссылки. Получается/(\b[^\s]+\b)(?!([^\[]*\]))(?!(\bhttp[^\s]+\b))/g
Составил выражение (?<=/icons\/).*\.png(?<=/icons\/).*?\.png
let words = ['набор', 'определенных', 'слов'];
let Reg = new RegExp(words.map(word => `.*(?=${word})`).join(''), 'i');
let text1 = 'какойто текст и набор определенных слов';
let text2 = 'какойто текст определенных слов';
Reg.test(text1);
// true
Reg.test(text2);
// false