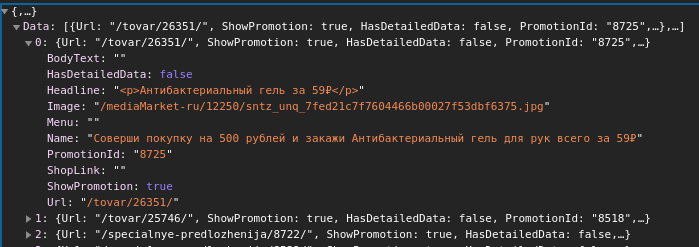
for card_link in card_list:
responce = requests.get(card_link, headers=headers)
soup = BeautifulSoup(responce.text, 'lxml')
card_product = soup.find("div", class_ = "card mt-4 my-4")
card_title = card_product.find("h3", class_ = "card-title").text
# card_text = card_product.find("h4", class_ = "card-text").text
card_price = card_product.find("h4").text
print(card_title, card_price)def get_skypes(number):
epieos_url = 'https://tools.epieos.com/skype.php'
epieos_params = {'data':number}
epieos_response = requests.post(epieos_url, data=epieos_params)
epieos_soup = BeautifulSoup(epieos_response.text, 'html5lib')
users = epieos_soup.select('div.col-md-4.offset-md-4.mt-5.pt-3.border') # Выбираем все div'ы со следующими классами
for user in users:
skype_name = user.select('p')[1].text.replace('Name : ','') # Выбираем второй div
skype_login = user.select('p')[2].text.replace('Skype Id : ','') # Выбираем третий div
print(f'\n<b>Скайп:</b> <a href="https://transitapp.com/redirect.html?url=skype://{skype_login}?chat">{skype_login}</a> | {skype_name}')
get_skypes("79999999999")
from bs4 import BeautifulSoup
import requests
def search_game(title):
URL = 'https://store.steampowered.com/search/results'
games_list = []
response = requests.get(URL,params={'term':title},headers={'user-agent':'hacked by hottabXP'})
soup = BeautifulSoup(response.text,'lxml')
games = soup.find('div', id='search_resultsRows').find_all('a',class_='search_result_row ds_collapse_flag')
for game in games:
title = game.find('span',class_='title').text.strip()
try: # На случай, если цена со скидкой
price = game.find('div',class_='col search_price responsive_secondrow').text.strip()
except:
price = game.find('strike').text
games_list.append({'title':title,'price':price})
return games_list
print(search_game("GTA 5"))[{'title': 'Grand Theft Auto V', 'price': ''}, {'title': 'Grand Theft Auto V: Premium Edition', 'price': '629₴'}, {'title': 'Grand Theft Auto V: Premium Edition & Great White Shark Card Bundle', 'price': '790₴'}, {'title': 'Grand Theft Auto V: Premium Edition & Megalodon Shark Card Bundle', 'price': '1 228₴'}, {'title': 'GTA Online: Shark Cash Cards', 'price': ''}, {'title': 'Grand Theft Auto V - Criminal Enterprise Starter Pack', 'price': '209₴'}, {'title': 'Grand Theft Auto V: Premium Edition & Whale Shark Card Bundle', 'price': '916₴'}, {'title': 'liteCam Game 5: 120 FPS Game Capture + Streamer', 'price': ''}, {'title': 'Assetto Corsa - Dream Pack 1', 'price': '129₴'}, {'title': 'Warhammer 40,000: Dawn of War III', 'price': '599₴'}, {'title': 'Memory Card Monsters - Expanded Content 5', 'price': '21₴'}, {'title': 'Fantasy Memory Card Game - Expansion Pack 5', 'price': '21₴'}, {'title': 'APB Reloaded', 'price': 'Free to Play'}, {'title': 'Shop Tycoon: Prepare your wallet', 'price': '119₴'}, {'title': '3dSunshine', 'price': 'Free'}, {'title': 'Druid', 'price': '20₴'}, {'title': 'Lazaretto', 'price': '129₴'}, {'title': "Rock 'N' Roll Defense", 'price': '21₴'}, {'title': '小黑盒加速器', 'price': 'Free To Play'}, {'title': 'Drop Hunt - Adventure Puzzle', 'price': '20₴'}, {'title': 'Carmageddon Max Pack', 'price': '169₴'}, {'title': 'Lamp Head', 'price': '27₴'}, {'title': 'Need for Drive - Open World Multiplayer Racing', 'price': '21₴'}, {'title': 'Crash Drive 3', 'price': '279₴'}, {'title': 'Retro City Rampage™ DX', 'price': '229₴'}, {'title': 'VCB: Why City 4k', 'price': '67₴'}, {'title': 'CS2D', 'price': 'Free To Play'}, {'title': 'ConflictCraft', 'price': '21₴'}, {'title': 'State of Anarchy: Master of Mayhem', 'price': '20₴'}, {'title': 'Geneshift', 'price': '229₴'}, {'title': '汉武大帝传', 'price': '149₴'}, {'title': 'Fix Me Up Doc! – Dark Humor', 'price': '21₴'}, {'title': 'Extreme Racing on Highway', 'price': '179₴'}, {'title': 'The Last Hope: Trump vs Mafia - North Korea', 'price': '21₴'}, {'title': 'Control Craft 3', 'price': '21₴'}, {'title': 'Zombie Killer Drift - Racing Survival', 'price': '21₴'}, {'title': 'Bugs Must Die / 异星特勤队', 'price': '199₴'}, {'title': 'Control Craft 2', 'price': '21₴'}, {'title': 'Hero Hunters - 杀手 3D 2K19', 'price': '119₴'}, {'title': 'USA Truck Simulator', 'price': '27₴'}, {'title': 'MechDefender - Tower Defense', 'price': '21₴'}, {'title': 'CYBER.one: Racing For Souls', 'price': ''}, {'title': 'VCB: Why City (Beta Version)', 'price': ''}, {'title': 'Mountain Taxi Driver', 'price': '21₴'}, {'title': 'The Kickstarter Avoidance Album', 'price': '21₴'}, {'title': 'Dino Zoo Transport Simulator', 'price': '27₴'}, {'title': 'Snow Clearing Driving Simulator', 'price': '169₴'}, {'title': 'Space Hero Line', 'price': '21₴'}, {'title': 'EDEN STAR', 'price': '279₴'}, {'title': 'liteCam Game: 100 FPS Game Capture', 'price': ''}]import requests
from bs4 import BeautifulSoup
import json
response = requests.get(
url='https://play.google.com/store/apps/details?id=ru.mail.mailapp&hl=ru&gl=US&showAllReviews=true',
headers={'user-agent':'Hacked by HottabXP!'})
soup = BeautifulSoup(response.text,"lxml")
dirty_comments = soup.find_all('script')[34].string # Методом тыка определяем, что json с коментами хранится
# в 35 теге <script> и преобразовываем данные внутри тега в строку
valid_json = dirty_comments[dirty_comments.find(' data:')+6:dirty_comments.find(', sideChannel')] # Вырезаем всё, что
# находится между data: (плюс 6 символов) и sideChannel
comments_json = json.loads(valid_json) # Тут уже работаем с обычным json
for comment in comments_json[0]:
user_comment = comment[4] # Комментарий пользователя
try:
author_answer = comment[7][1] # Ответ на комментарий пользователя (может быть None)
except:
author_answer = '' # Если None, тогда в author_answer помещаем пустую строку
print(user_comment)
from bs4 import BeautifulSoup
html = '''
<body>
<img src="https://yandex.com/main.jpg">
</body>
'''
soup = BeautifulSoup(html,'html.parser')
tag = soup.img
tag['src'] = 'https://google.com/main.jpg'
print(soup)<body>
<img src="https://google.com/main.jpg"/>
</body>import requests
import json
html = requests.get('https://xn--80aesfpebagmfblc0a.xn--p1ai/information/').text
start = '<cv-spread-overview :spread-data=' # Начало обрезки
end = "isolation-data" # Конец обрезки
raw_json_data = html[html.find(start)+34:html.find(end)-3] # Вырезаем json из html страницы
json_data= json.loads(raw_json_data)
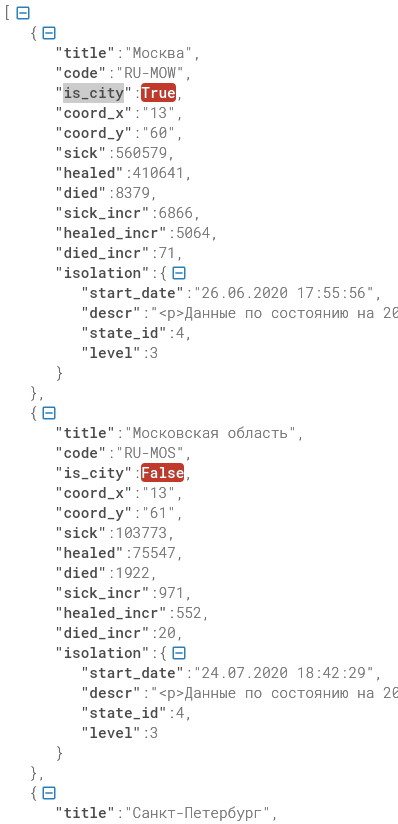
for item in json_data:
title = item['title'] # Город
sick = item['sick'] # Выявлено
healed = item['healed'] # Выздоровело
died = item['died'] # Умерло
sick_incr = item['sick_incr'] # Новые
healed_incr = item['healed_incr'] #В ыздоровело за сутки
died_incr = item['died_incr'] # Умерло за сутки
print(f'{title} - {sick} - {healed} - {died} - {sick_incr} - {healed_incr} - {died_incr}')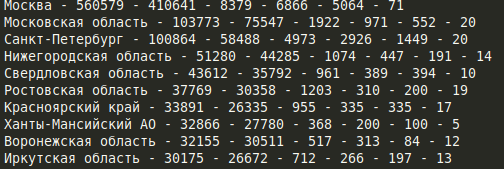
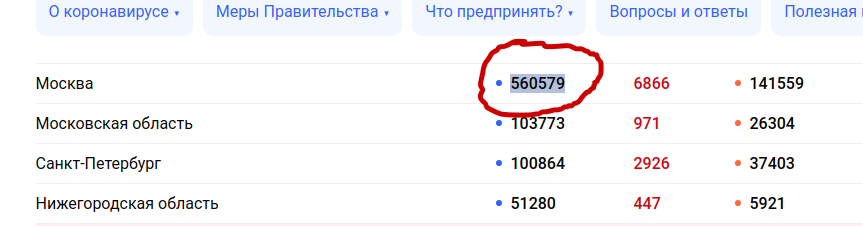

get_text().replace(',','').text().replace(',','')
import requests
import json
import requests
headers = {
'content-type': 'application/json',
}
data = '''{"filter":{"rated":"Any",
"orderBy":"WithRates",
"tag":"",
"reviewObjectId":276,
"reviewObjectType":"banks",
"page":"1",
"pageSize":20,
"locationRoute":"",
"regionId":"",
"logoTypeUrl":"banks"
}}'''
response = requests.post('https://www.sravni.ru/provider/reviews/list',data=data,headers=headers)
reviews = json.loads(response.text)
total = reviews['total']
print(f'Всего отзывов: {total}')
for review in reviews['items']:
title = review['title']
text = review['text']
print(f'{title} - {text}')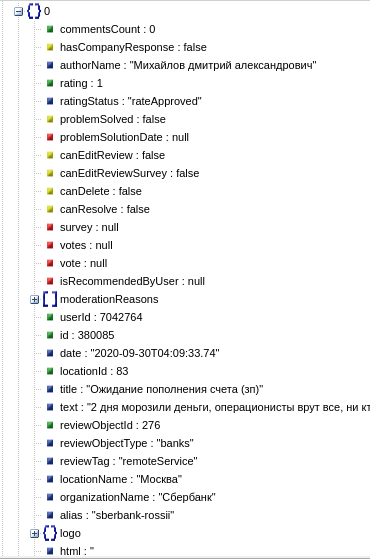
import requests
from bs4 import BeautifulSoup
import json
response = requests.get('https://vk.com/id1')
soup = BeautifulSoup(response.text,'html.parser')
avatar = soup.find('div',id='page_avatar').a.get('onclick')
json_raw = avatar[avatar.find('{'):avatar.rfind('}')+1] #Здесь вытаскивает json
json_data = json.loads(json_raw)
print(json_data['temp']['x']) # Получаем из json url аватаркиfor item in items:
try:
d.append({
'title': item.find('div', class_='item-name').text,
'address': item.find('span', class_='item-address').text,
'p': item.find('div', class_='item-description').text.replace('\xa0','')
})
except:
pass
my_div = soup.find('div',class_='rating-box__active').get('style')
print(my_div) # Вывод - width: 100%
print(my_div[7:-1]) # Вывод - 100import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
# body
# bfor tag in soup.find_all(re.compile("t")):
print(tag.name)
# html
# titleimport requests
headers = {'user-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
url = 'https://www.youtube.com/watch?v=pSWOcXg703s'
response = requests.get(url,headers=headers)
html = response.text
first_1 = html.find('og:title" content="')+19
second_2 = html.find('">',first_1)
title = html[first_1:second_2]
first = html.find('videoViewCountRenderer')+72
second = html.find('"}]}',first)
views = html[first:second]
first_ = html.find('likeStatus":"INDIFFERENT","tooltip"')+37
second_ = html.find('"}},',first_)
likes = html[first_:second_].replace(' ','').split('/')
print(f'Название видео: {title}')
print(f'Сейчас смотрят: {views}')
print(f'Лайков: {likes[0]}')
print(f'Дизлайков: {likes[1]}')Название видео: Elon Musk Live: Bitcoin BTC Talk, BTC Mass Adoption & SpaceX update [April, 2020]
Сейчас смотрят: 59 365
Лайков: 2 542
Дизлайков: 153