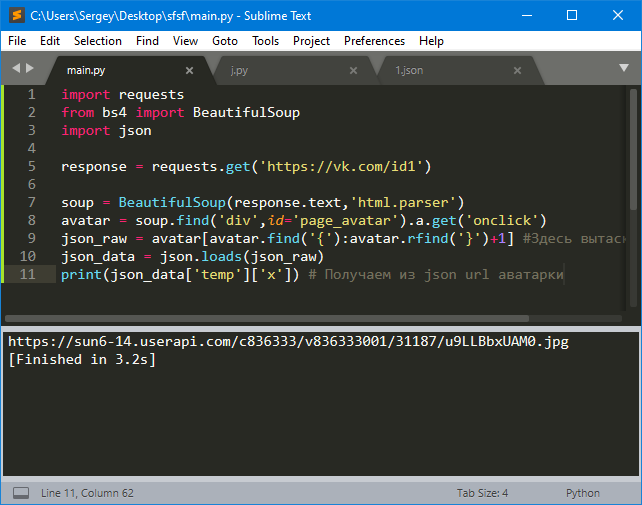
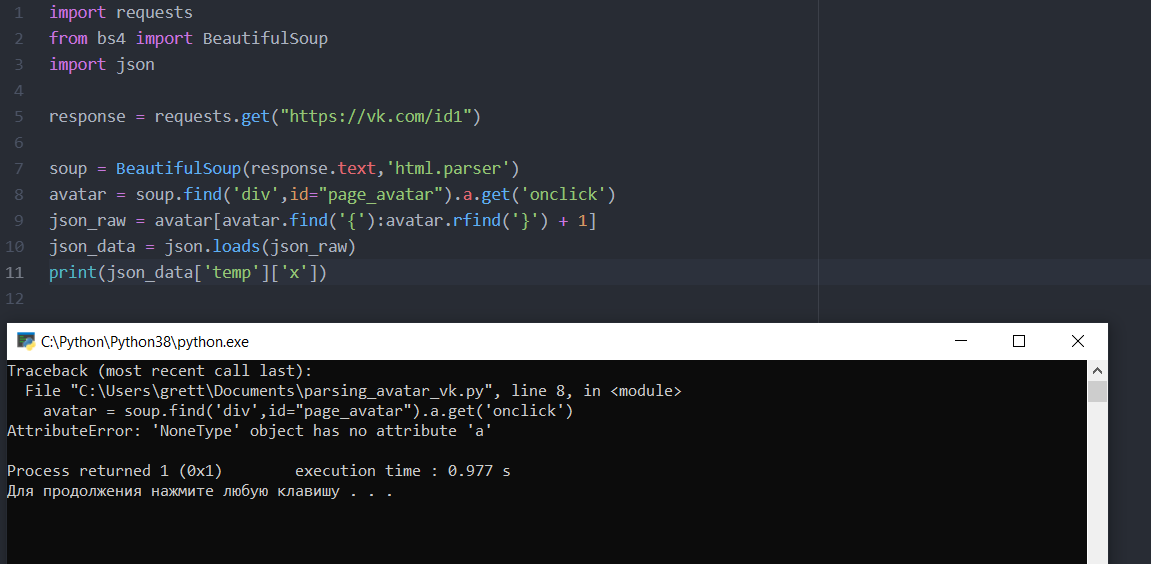
import requests
from bs4 import BeautifulSoup
import json
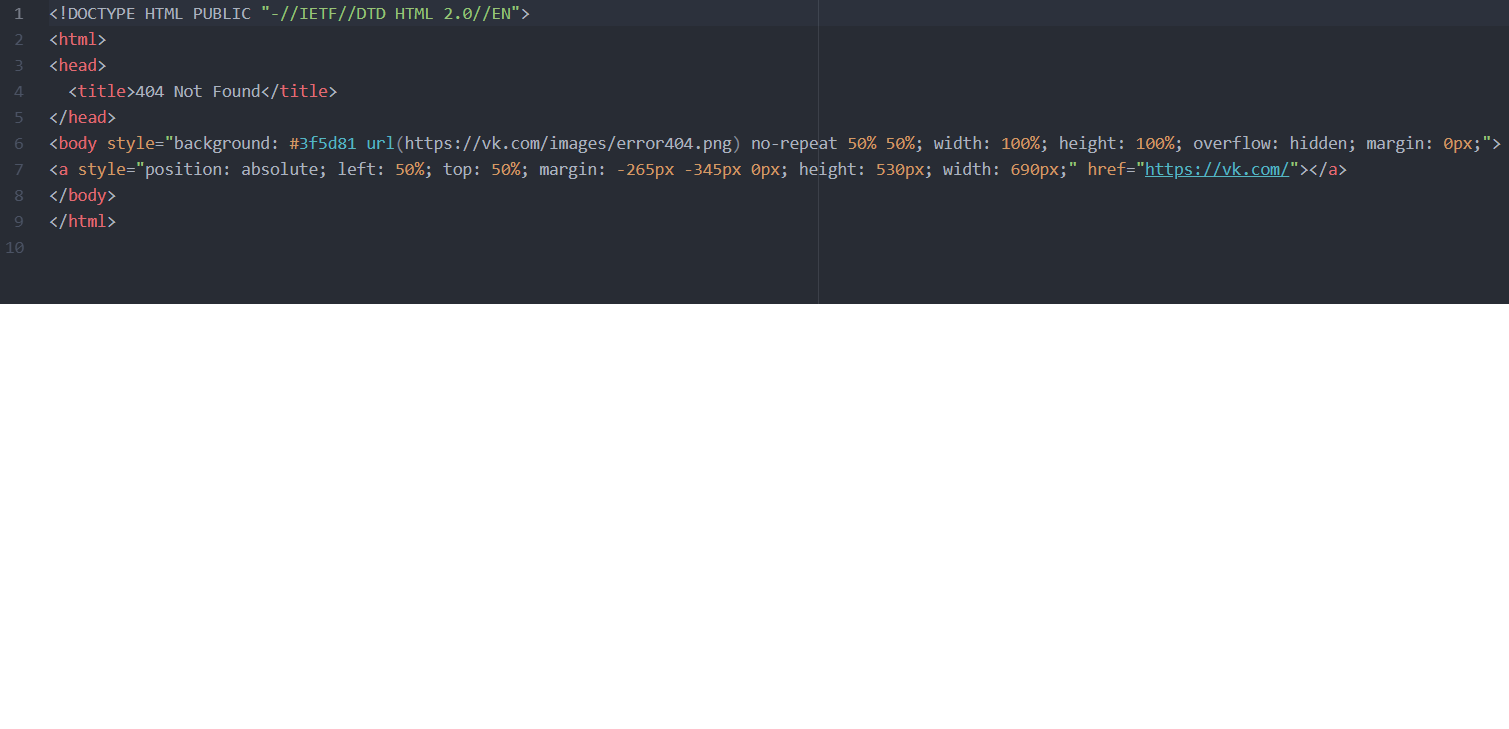
response = requests.get('https://vk.com/id1')
soup = BeautifulSoup(response.text,'html.parser')
avatar = soup.find('div',id='page_avatar').a.get('onclick')
json_raw = avatar[avatar.find('{'):avatar.rfind('}')+1] #Здесь вытаскивает json
json_data = json.loads(json_raw)
print(json_data['temp']['x']) # Получаем из json url аватарки